
С появлением компьютеров перед человеком встал целый ряд новых проблем, связанных с передачей и хранением информации. Ввод данных всегда требовал значительных затрат времени и сил, а стремление свести эти затраты к минимуму заставляет постоянно работать над способами перевода знаковой системы, которой пользуется человек, на тот язык, который понятен машине. Перфокарты, а потом клавиатура не до конца решили эту проблему, так как эти способы передачи информации не являются естественными для человека, а потому они неэффективны, неэкономичны и, кроме того, требуют длительного освоения.
При современных масштабах распространения ПК работать с ними приходится не только специалистам, владеющим быстрым набором с клавиатуры, но и малоподготовленным пользователям, для которых ввод информации выливается в отдельную проблему. Любой поработавший с современным графическим пакетом согласится, что около десятка движений мышью при создании какого-либо эффекта порой можно заменить одним словом. Таким образом, задача состоит в том, чтобы научить компьютер понимать без посредника тот язык, на котором говорят люди между собой, то есть придумать алгоритм распознавания звукового образа.
На уровне письменного текста указанная проблема уже частично решена: такие программы, как FineReader или CuneiForm, позволяют вводить через сканер любой напечатанный текст. Однако в данном случае мы имеем дело с уже готовым текстом, а ввод информации в процессе его создания представляет определенную сложность. Пока человек не научится телепатически передавать свои мысли, единственным инструментом, служащим ему для этого, является речь, и потому каждому пользователю ПК очень хотелось бы, чтобы его помощник слышал, а главное, понимал своего хозяина.
1. ИСТОРИЯ СОЗДАНИЯ И РАЗРАБОТКИ СИСТЕМ
Соединенные Штаты Америки, конец 60-х годов XX века: «Три», — сказал Валтер Кронкит (Walter Cronkite), ведущий научно-популярной программы «XXI век», во время демонстрации новейших разработок в области распознавания речи. Компьютер распознал это слово как «четыре». «Идиот», -пробормотал Валтер. «Этого слова нет в словаре», — ответил компьютер.
Хотя первые разработки в области распознавания речи относятся еще к 1920-м годам, первая система была создана только в 1952 году компанией Bell Laboratories (сегодня она входит в состав Lucent Technologies).
А первая коммерческая система была создана еще позже: в 1960 году IBM объявила о разработке такой системы, но на рынок программа так и не вышла.
Технологии ввода информации
... ввода графической информации в компьютер. Функция сканера — получение электронной копии документа, созданного ... на базе электронных технологий, пока еще ... устройств ввода графической информации являются системы автоматизированного ... гг. в персональных компьютерах. Манипулятор «мышь» - координатное устройство, предназначенное для управления курсором (указателем) мыши и ввода управляющей информации. ...
Затем, в 1970-х годах, авиакомпания Eastern Airlines в США установила дикторозависимую систему отправки багажа: оператор называл пункт назначения — и багаж отправлялся в путь. Однако из-за количества допущенных ошибок система так и не прошла испытательный срок.
После этого разработки в данной области если и велись, то достаточно вяло. Даже в 1980-х годах реальных коммерческих приложений с использованием систем распознавания речи было довольно мало.
2. ОПИСАНИЕ СОВРЕМЕННОГО СОСТОЯНИЯ ВОПРОСА
Как хорошо было раньше! Позвонив в справочную, можно было побеседовать с девушкой-оператором и даже назначить ей свидание. Теперь же на том конце провода слышится приятный, но неживой женский голос, предлагающий набрать 1 для получения такой-то информации, 2 — для связи с тем-то, 3 — для выхода в меню и т.д. Все чаще доступ к информации контролируется системой, а не человеком. В этом есть своя логика: однообразная, неинтересная работа выполняется не человеком, а машиной. И для пользователя процедура получения информации упрощается: назвал определенный набор цифр — получил нужную информацию .
Существующие технологии распознавания речи не имеют пока достаточных возможностей для их широкого использования, но на данном этапе исследований проводится интенсивный поиск возможностей употребления коротких многозначных слов (процедур) для облегчения понимания. Распознавание речи в настоящее время нашло реальное применение в жизни, пожалуй, только в тех случаях, когда используемый словарь сокращен до 10 знаков, например при обработке номеров кредитных карт и прочих кодов доступа в базирующихся на компьютерах системах, обрабатывающих передаваемые по телефону данные. Так что насущная задача — распознавание по крайней мере 20 тысяч слов естественного языка — остается пока недостижимой. Эти возможности пока недоступны для широкого коммерческого использования. Однако ряд компаний своими силами пытается использовать уже существующие в данной области науки знания.
Существующие сегодня системы распознавания речи основываются на сборе всей доступной (порой даже избыточной) информации, необходимой для распознавания слов. Исследователи считают, что таким образом задача распознавания образца речи, основанная на качестве сигнала, подверженного изменениям, будет достаточной для распознавания, но тем не менее в настоящее время даже при распознавании небольших сообщений нормальной речи, пока невозможно после получения разнообразных реальных сигналов осуществить прямую трансформацию в лингвистические символы, что является желаемым результатом.
Сегодня в этом направлении работают уже не десятки, а сотни исследовательских коллективов в научных и учебных заведениях, а также в крупных корпорациях. Об этом можно судить по таким международным форумам ученых и специалистов в области речевых технологий, как ICASSP, EuroSpeech, ICPHS и др. Результаты работы, на которую, как у нас образно говорят, «навалились всем миром», трудно переоценить.
Уже в течение нескольких лет голосовые навигаторы, или системы распознавания команд, успешно применяются в различных областях деятельности. Например, call-центр OmniTouch поставленный Ватикану компанией Alcatel, использовался для обслуживания мероприятий, проходивших в рамках празднования 2000-летия Христа. Паломник, звонивший в call-центр, излагал свой вопрос, и система автоматического распознавания речи «выслушивала» его. Если система определяла, что вопрос задан по часто встречающейся теме, например о расписании мероприятий или адресах гостиниц, то включалась предварительно сделанная запись. При необходимости уточнить вопрос предлагалось речевое меню, в котором голосом надо было указать один из пунктов. Если же система распознавания определяла, что предварительно записанного ответа на заданный вопрос нет, то происходило соединение паломника с оператором-человеком.
Навигационные системы в современном мире
... средства отображения картографической информации. Цель данной работы - изучение общих принципов функционирования навигационных систем и навигационных приемников, вопросы организации программного обеспечения приемников, их эксплуатации и перспективы развития и модернизации. ...
В Швеции не так давно была открыта автоматическая телефонная справочная служба, использующая программу распознавания речи компании Philips. За первый месяц работы службы Autosvar, которая начала действовать без официального объявления, ее услугами воспользовались 200 тыс. клиентов. Человек должен набрать определенный номер и после ответа автоматического секретаря назвать интересующий его раздел информационного справочника.
Новая услуга предназначена в основном для частных клиентов, которые предпочтут ее из-за значительно меньшей стоимости услуг. Служба Autosvar является первой системой такого рода в Европе (в США испытания аналогичной службы в компании AT&T были начаты в декабре 2002 года).
Вот несколько примеров использования этой технологии в США.
Риэлтеры часто обращаются к услугам компании Newport Wireless. Когда риэлтер проезжает на машине по улице и видит возле какого-нибудь дома табличку «Продается», он звонит в Newport Wireless и запрашивает сведения о доме с таким-то номером, находящемся на такой-то улице. Автоответчик приятным женским голосом рассказывает ему о метраже дома, дате постройки и владельцах. Вся эта информация находится в базе данных Newport Wireless. Риэлтерам остается только выдать сообщение клиенту. Абонентская плата — около 30 долл. в месяц.
Джули, виртуальный агент компании Amtrak, обслуживает железнодорожных пассажиров с октября 2001 года. Она по телефону сообщает о расписании поездов, об их прибытии и отправлении, а также производит бронирование билетов. Джули — это продукт компании SpeechWorks Software и Intervoice Hardware. Она уже увеличила показатель удовлетворенности пассажиров на 45%; 13 из 50 клиентов получают всю нужную информацию из «уст» Джули. Раньше компания Amtrak использовала тоновую систему справки, однако показатель удовлетворенности тогда был меньше: всего 9 клиентов из 50.
В Amtrak признаются, что свою цену (4 млн. долл.) Джули окупила за 12-18 месяцев. Она позволила не нанимать на работу целую команду служащих. A British Airways экономит 1,5 млн. долл. в год, используя технологию от Nuance Communications, которая тоже автоматизирует справочную службу.
Недавно Sony Computer Entertainment America представила Socom — первую видеоигру, в которой игроки могут отдавать устные приказы бойцам из «Deploy grenades». В игре стоимостью 60 долл. применена технология ScanSoft. В прошлом году было продано 450 тыс. таких игр, что сделало Socom безусловным лидером продаж компании.
Даже в медицине технология распознавания голоса нашла свое место. Уже разработаны аппараты осмотра желудка, послушные голосу врача. Правда, эти аппараты, по словам специалистов, пока еще несовершенны: у них замедленная реакция на приказы врача. Но все еще впереди. В Мемфисе VA Medical Center вложил 277 тыс. долл. в программу Dragon, позволяющую врачам и медсестрам надиктовывать информацию в базу данных компьютера. Вероятно, скоро не нужно будет мучиться, чтобы разобрать в медицинской карте почерк врача.
Развитие связной речи младших школьников на х русского языка
... Цель курсовой работы - обобщить данные теории и практики развитая речи учащихся на уроках русского языка, привести эти данные в определенную систему, показать пути решения конкретных вопросов методики развития речи. ... литературе. Лингвисты, как правило, пишут о речи в плане ее сопоставления с языком. Для них язык - "это система материальных единиц, служащих общению людей и отражаемых в ...
Уже сотни крупных компаний используют технологию распознавания голоса в своей продукции или в услугах; в их числе — AOL, FedEx, Honda, Sony, Sprint, T. Rowe Price, United Airlines и Verizo. По оценкам экспертов, рынок голосовой технологии достиг в 2002 году порядка 695 млн. долл., что на 10% выше, чем в 2001 году.
Авиакомпания United Airways внедрила автоматическую справочную службу еще в 1999 году. Автоматические системы обработки телефонных звонков эксплуатируются такими компаниями, как инвестиционный банк Charles Schwab & Со, розничная сеть Sears, сеть супермаркетов Roebuck. Американские операторы беспроводной связи (AT&T Wireless и Sprint PCS) уже больше года используют подобные программы и предоставляют услуги голосового набора. И хотя сейчас лидером по количеству call-центров такого типа является Америка, в последнее время выгоду от систем распознавания речи начали осознавать и в Европе. Например, швейцарская служба железных дорог уже предоставляет своим немецкоязычным пассажирам услуги, аналогичные тем, что предлагает United Airways.
3. КАК ПРОИСХОДИТ РАСПОЗНАВАНИЕ РЕЧИ
Процесс распознавания речи может быть разделен на две основные фазы: оцифровка и декодирование. На первой фазе входной аудиосигнал записывается и разбивается на фрагменты. На фазе декодирования полученная информация анализируется на основе использования различных моделей и алгоритмов
Алгоритмы декодирования могут опираться на образцы как целых слов, так и отдельных частей слов. Самой малой частью слова является фонема, и любому языку обычно достаточно 40-60 фонем, чтобы описать произношение всех слов.
Наиболее точными с точки зрения распознавания являются модели, основанные на распознавании слов целиком. Однако они могут использоваться лишь в системах со словарями небольшого объема
Модели, основанные на фонемной структуре, являются гораздо более универсальными и в значительной мере решают проблему объема словаря.
В основу предлагаемого подхода, и это является его главной отличительной чертой, положено сложное (иерархическое и многоярусное) представление пространства акустико-фонетических признаков и фонетических единиц, задействованных в процессе распознавания. Ниже в самом общем виде описываются основные этапы процедуры формирования такого представления и способ его использования непосредственно в процессе распознавания.
? Первоначально для речевого сигнала, который будет использоваться в процессе обучения распознающей системы, составляется детальная сегментная транскрипция. Сегменты – аллофоны фонем – описываются посредством двух основных классов стандартных фонетических признаков – автономных и иерархических. Автономные признаки (такие как назализация, напряженность, лабиализация и др.) определяют «многоярусный» характер представления акустико-фонетического пространства; они обладают относительной независимостью, поскольку их наличие или отсутствие никак не предопределяется и не ограничивается реализацией других признаков, и могут использоваться для описания фонетических единиц любого уровня иерархии. Иерархический признак, напротив, характеризуется обязательной соотнесенностью с другими классификационными признаками. Так, например, только согласный звук может быть взрывным, и только взрывной, в свою очередь, может быть реализован с носовым взрывом. В целом для подробного фонетического описания используется приблизительно 40 фонетических признаков, автономных и иерархических. Все аллофоны, затранскрибированные с помощью описанного выше набора признаков, далее используются в процессе обучения системы распознавания речи. Процесс сегментации и транскрибирования речевого сигнала может выполняться как вручную (экспертом-фонетистом), так и в (полу-)автоматическом режиме (особенно в случае использования больших объемов речевого материала), с последующей экспертной коррекцией.
Диплом №4141 Обогащения словаря у детей старшего дошкольного ...
... ребенком в процессе общения . Ограниченный словарный запас многократное использование слов с одинаковым лексическим значением делают речь детей ... Обогащение словарного запаса происходит в случае ознакомления с окружающим миром во всех видах деятельности ребенка ... Особенности развития речи старших дошкольников с общим недоразвитием речи Словарь – это слова основные единицы речи которые обозначают ...
? Составляется словарь системы распознавания речи, при этом каждое слово получает транскрипционное представление. За основу принимается стандартное (полностильное) произнесение, определяемое как исходная транскрипция слова (ИТС).
В дальнейшем, в процессе распознавания, каждое слово будет соотноситься с имеющимися в словаре ИТС.
? Далее, в рамках разработки расширенного пространства слова, осуществляется генерация всех теоретически возможных вариантов реализации данного слова — т.н. «аллофонных сетей». При генерации аллофонных сетей используются фонетические правила модификации, которые позволяют для любой русской фонемы в любом контексте спрогнозировать все возможные модификационные сценарии. Данные модификационные правила формулировались на основе сведений, содержащихся в литературе [например, 4], исследовательского опыта и лингвистических знаний экспертов, с поправкой на реальные произносительные статистики, полученные в процессе обработки имеющегося речевого материала. Модификационные правила дополняются факторами влияния, наличие или отсутствие которых в конкретной речевой реализации определяет относительные вероятности типов и степеней модификационных изменений фонетической единицы, предписанной в ИТС. Подробнее о формулировании и применении модификационных правил см. в следующем разделе.
? Как уже говорилось выше, аллофонные сети, являясь необходимым элементом фонетического описания, сами по себе не способны эффективно моделировать произносительную вариативность в рамках задачи автоматического распознавания речи. Проблема решается посредством последующей иерархизации пространства произносительной вариативности слова за счет введения определенного количества обобщающих уровней описания. Обобщение осуществляется лингвистами (экспертами-фонетистами) на основе наблюдений за звучащей речью. При использовании достаточно больших баз речевых данных возможно применение автоматической процедуры для обобщения аллофонных транскрипций. Обобщения могут затрагивать как один, так и несколько уровней иерархии. Не только каждая элементарная единица (фонема или один из ее аллофонов), но и практически любая обобщенная мета-единица (исключая самый верхний уровень иерархии) может в потенциале входить в любое число других мета-единиц более высоких уровней, так что мета-единицы имеют различный размер, в зависимости от количества элементарных исходных единиц, входящих в их состав, и/или их обобщающей силы. При объединении фонетических единиц в мета-классы основным фактором является адекватность в отражении произносительной реальности, которая не всегда соответствует традиционным фонологическими принципам классификации фонетических единиц и признаков. Так, например, среди выделенных нами мета-единиц есть не только традиционные широкие фонетические классы, такие как “гласный”, “согласный”, “закрытый”, “мягкий” и т.д., но и некоторые нетрадиционные объединения, например, “передний” (включает гласные переднего ряда, мягкие и переднеязычные согласные), “губной” (лабиализованные гласные и губные согласные), “полугласный/полусогласный” и др. Кроме того, допустимыми являются мета-единицы, включающие аллофоны различных фонем и не сводимые к простой комбинации соответствующих фонем (это означало бы, что все их аллофоны входят в данную мета-единицу, а это не всегда имеет место).
Формирование грамматического строя речи у детей старшего дошкольного ...
... Целенаправленность, систематичность, последовательное усложнение работы по формированию грамматического строя речи. 4. Разнообразие используемых методов и приемов по формированию умений составлять словосочетания. метод исследования 1.Словосочетание как единица синтаксиса Существует несколько ...
Аллофоны группируются также на основе контекстов их реализации, что позволяет учитывать различные типы систематической аллофонической вариативности, наблюдаемой в связной речи. В результате объединения детализованных (аллофонных), промежуточных (фонемных и аллофонных) и обобщенных (мета-фонемных) транскрипционных представлений для каждого слова генерируется иерархическая многоярусная сеть (ИМС), которая обеспечивает полноценный учет и эффективную организацию всех допустимых произносительных вариантов слова в различной степени подробности.
? Иерархическая многоярусная сеть (ИМС), в которую организованы все единицы и мета-единицы, представляет собой односвязное многоярусное дерево. На заданном уровне дерева каждая пара единиц или мета-единиц может быть либо независимой (автономной), либо иерархически связанной с высшим уровнем (иерархической).
Такое структурированное представление позволяет установить меру близости для любой заданной пары звуков. На каждом узле ИМС имеется иерархическая весовая функция (ИВФ), описывающая относительную значимость добавления /отрицания данного фонетического признака для распознавания конкретной фонемы в данном слове. Весовые функции первоначально отражают статистическую информацию о влиянии чисто фонетического уровня реализации звуков (выводимую на основе фонетических модификационных правил) и имеют поправки за счет общелингвистических факторов влияния – уровня (фонетического) слова (позиция, контекст и др.), уровня лексикона (частотность слова, омонимия и т.п.), уровня произнесения (темп, стиль).
Такая структура признакового описания единиц и мета-единиц позволяет достаточно просто и стандартизовано определять меру сходства между собой различных вариантов аллофонной реализации слова с учетом многих лингвистических и экстралингвистических факторов.
? В процессе обучения системы для каждой единицы и мета-единицы, включенной в ИМС, создается шаблон. Для простых единиц такие шаблоны получаются стандартным способом (например, с помощью СММ).
Шаблоны для мета-единиц имеют иерархическую структуру и составляются из шаблонов простых единиц, входящих в состав данной мета-единицы. Также существует возможность создания дополнительных шаблонов непосредственно для мета-единиц.
? В процессе распознавания происходит сравнение входных данных и имеющихся ИТС. При этом с учетом значений иерархической весовой функции устанавливается мера сходства между найденной текущей реализацией распознаваемого слова и ИМС, построенной по исходной транскрипции сравниваемого слова (ИТС).
Биометрические системы контроля доступа
... вложившие в разработку этих систем огромные, по тем временам, средства, были вынуждены поддерживать дальнейшие работы по совершенствованию технологической и аппаратной частей систем. На середину 80- ... безопасности, а именно распознавание личности. По сравнению с традиционными, биометрические методы идентификации личности имеют ряд преимуществ, а именно: биометрические признаки очень трудно ...
Чем выше значение меры близости сравниваемых транскрипций с учетом ИВФ, тем более вероятным является распознанный вариант слова.
-
АНАЛИЗ ОСНОВНЫХ ПРОБЛЕМ
На первый взгляд все очень просто: если печатный текст распознается, то и речь тоже можно распознать, ведь компьютеру все равно, что обрабатывать — звук или рисунок. Казалось бы, нужно только разделить полученное изображение или звуковой поток на повторяющиеся стандартные образы, сопоставить их с используемыми нами знаками и дать им определенные числовые значения, по которым их будет узнавать машина. Все бы так и было, если бы печатный текст и речь были действительно аналогичными методами передачи информации, но в действительности они очень непохожи, и дело здесь вовсе не в типе носителя информации. Человеческую речь скорее можно сравнить с рукописным текстом, который, как и человеческая речь, очень зависит от индивидуальных характеристик каждого человека. Почерк и тембр голоса уникальны и практически неповторимы, и эти непредсказуемые в каждом случае параметры серьезно затрудняют вычленение и систематизацию знаковых образов.
Несмотря на перечисленные трудности, системы распознавания речи совершенствуются довольно быстро и постепенно начинают конкурировать с клавиатурным вводом. При этом необходимо подчеркнуть, что пока компьютер еще весьма далек от человека, улавливающего интонации и настроение собеседника.
Обычно человек, впервые услышав о технологии распознавании речи, полагает, что для надиктовывания текста системе, распознающей речь, не требуется особых навыков, однако это не так. В отличие от клавиатурного, речевой ввод помимо основной информации несет и данные о поле говорящего, о его возрасте, состоянии здоровья, настроении, отношении к передаваемой информации, а также много других дополнительных сведений. Для распознавания речи абсолютное большинство этих данных — не помощь, а помеха, то есть как для разговора по телефону, так и для надиктовывания текста системе распознавания от человека требуется так или иначе приспосабливать речь к этим
Сегодня нам кажется, что для того, чтобы эффективно пользоваться телефоном, не нужны никакие навыки. Это связано с тем, что обучение происходит исподволь: с раннего возраста дети наблюдают, как взрослые разговаривают по телефону, и незаметно для себя приобретают определенные умения. В подтверждение этому приведем небольшую цитату из «Почтово-телеграфного журнала» за 1902 год:
«Человек, редко прибегающий к посредству телефона, будет говорить или слишком громко, или слишком тихо, и лишь после некоторого навыка можно научиться приспособить свою речь таким образом, чтобы она внятно передавалась телефоном. При этом, однако, не безразлично, на каком языке происходит разговор, так как некоторые языки к этому более пригодны, чем другие. Такое различие особенно ясно сказалось со времени открытия телефонного сообщения между Германией и Францией. Самым неудобным из европейских языков для телефонной передачи оказывается английский язык, изобилующий шипящими звуками и представляющий при телефонировании большие затруднения, так как их очень легко смешать с обычным мешающим шумом в аппаратах».
Итак, речевой ввод информации предъявляет
-
говорить следует не слишком громко и не слишком тихо. Лучше всего — обычным спокойным голосом.
Повышенные интонации несут много побочных данных, вследствие чего процент распознавания падает;
-
произносить слова нужно монотонно, но четко. Не должны проглатываться окончания, так как в отличие от человека компьютер пока не может следить за контекстом и додумывать окончания;
-
чем меньше посторонних шумов, тем лучше;
-
надо стараться поддерживать постоянное расстояние до микрофона;
-
в микрофон не должно попадать придыхание, поэтому микрофон нужно держать не прямо напротив рта, а приблизительно на сантиметр вправо и на сантиметр ниже.
Плохое аппаратное обеспечение тоже является источником проблем для распознавания речи, поэтому качественный микрофон и хорошая звуковая плата со встроенным фильтром шумов могут значительно улучшить работу системы распознавания речи. Но когда все трудности решены, перед пользователем программы распознавания звучащей речи открываются совершенно новые возможности. Во-первых, скорость ввода любого текста увеличивается в несколько раз по сравнению с вводом с клавиатуры; при этом затраты необходимых усилий уменьшаются, а обучение вообще не нужно, так как говорить мы все умеем. Во-вторых, такая программа позволяет управлять другими приложениями и операционной системой в целом с помощью голосовых команд, что очень облегчает и ускоряет работу за компьютером.
Наша страна преподносит разработчикам систем распознавания русской речи еще один сюрприз — диалекты и говоры: необходимо также учитывать различия в произношении в разных регионах России. Как правило, подобные проблемы решаются с помощью предварительной настройки. А технологии, разработанные специалистами фирмы VoiceLock, позволяют настраивать программу всего за несколько минут.
Главная проблема, возникающая при разработке САРР (системы автоматического распознавания речи), заключается в вариативном произношении одного и того же слова как разными людьми, так и одним и тем же человеком в различных ситуациях. Человека это не смутит, а вот компьютер — может. Кроме того, на входящий сигнал влияют многочисленные факторы, такие как окружающий шум, отражение, эхо и помехи в канале. Осложняется это и тем, что шум и искажения заранее неизвестны, то есть система не может быть подстроена под них до начала работы.
Однако более чем полувековая работа над различными САРР дала свои плоды. Практически любая современная система может работать в нескольких режимах. Во-первых, она может быть зависимой или независимой от диктора. Зависимая от диктора система требует специального обучения под конкретного пользователя, чтобы точно распознавать то, что он говорит. Для обучения системы пользователю надо произнести несколько определенных слов или фраз, которые система проанализирует и запомнит результаты. Этот режим обычно используется в системах диктовки, когда с системой работает один пользователь.
Дикторонезависимая система может быть использована любым пользователем без обучающей процедуры. Этот режим обычно применяется там, где процедура обучения невозможна, например в телефонных приложениях. Очевидно, что точность распознавания дикторозависимой системы выше, чем у дикторонезависимой. Однако независимая от диктора система удобнее в использовании, например она может работать с неограниченным кругом пользователей и не требует обучения.
Во-вторых, системы делятся на работающие только с изолированными командами и на способные распознавать связную речь. Распознавание речи является значительно более сложной задачей, чем распознавание отдельно произносимых слов. Например, при переходе от распознавания изолированных слов к распознаванию речи при словаре в 1000 слов процент ошибок увеличивается с 3,1 до 8,7, кроме того, для обработки речи требуется в три раза больше времени.
Режим изолированного произнесения команд наиболее простой и наименее ресурсоемкий. При работе в этом режиме после каждого слова пользователь делает паузу, то есть четко обозначает границы слов. Системе не требуется самой искать начало и конец слова в фразе. Затем система сравнивает распознанное слово с образцами в словаре, и наиболее вероятная модель принимается системой. Этот тип распознавания широко используется в телефонии вместо обычных DTMF-методов 1 .
Режим слитного произнесения более натурален и близок пользователю. При этом предполагается, что система сама различит границы слов во фразе. Однако этот режим требует гораздо больше системных ресурсов и памяти, а точность распознавания ниже, чем в предыдущем режиме. Почему это так? Причин несколько. Во-первых, при слитной речи произнесение слов менее аккуратно, чем в «режиме PIN-кода», то есть когда каждое слово произносится отдельно. Во-вторых, скорость речи даже у одного человека разная. Он может задуматься, засомневаться, забыть слово. В разговорной речи часто встречаются слова-паразиты: «ну», «а», «вот». Кроме того, границы слов часто смазываются, произносятся нечетко, что затрудняет работу системы.
Дополнительные вариации в речи возникают также из-за произвольных интонаций, ударений, нестрогой структуры фраз, пауз, повторов и т.д.
На стыке слитного и раздельного произнесения слов возник режим поиска ключевых слов. В этом режиме САРР находит заранее определенное слово или группу слов в общем потоке речи. Где это может быть использовано? Например, в подслушивающих устройствах, которые включаются и начинают запись при появлении в речи определенных слов, или в электронных справочных. Получив запрос в произвольной форме, система выделяет смысловые слова и, распознав их, выдает необходимую информацию.
Размер используемого словаря — важная составляющая САРР. Очевидно, что чем больше словарь, тем выше вероятность того, что система ошибется. Во многих современных системах есть возможность или дополнять словари по мере необходимости новыми словами, или подгружать новые словари. Обычный уровень ошибок для дикторонезависимой системы с изолированным произнесением команд — около 1% для словаря в 100 слов, 3% -для словаря в 600 слов и 10% — для словаря в 8000 слов.
____________________________________________________________________________
1 Многочастотный код 2 из 8 (или DTMF — Dual Tone Multiple Frequency) в настоящее время является все более широко распространяющимся телефонным стандартом. Данный стандарт вытесняет устаревшие импульсные сигналы. Помимо набора номера данный метод сигнализации находит множество других применений, таких как передача данных с небольшой скоростью по обычному телефонному каналу. Примером такого использования служит дистанционное управление домашним автоответчиком или иной техникой с другого телефона или использование дополнительных услуг в телефонной сети.
Кодек DTMF состоит из кодера (передатчика), который переводит нажатия клавиш (на телефонной клавиатуре) или цифровую информацию в двухтональные сигналы, а декодер, соответственно, определяет присутствие и информационное содержание двухтональной посылки во входящем сигнале.
4.1 МЕТОДЫ И МОДЕЛИ
Для успешного распознавания речи следует решить следующие задачи:
-
обработку словаря (фонемный состав),
-
обработку синтаксиса,
-
сокращение речи (включая возможное использование жестких сценариев),
-
выбор диктора (включая возраст, пол, родной язык и диалект),
-
тренировку дикторов,
-
выбор особенного вида микрофона (принимая во внимание направленность и местоположение микрофона),
-
условия работы системы и получения результата с указанием ошибок.
Проводится процесс, первым шагом которого является первоначальное трансформирование вводимой информации для сокращения обрабатываемого объема так, чтобы ее можно было бы подвергнуть компьютерному анализу. Примером является «техника сопоставления отрезков», позволяющая сократить вводимую информацию с 50’000 до 800 битов в секунду. Следующим этапом является спектральное представление речи, получившееся путем преобразования Фурье. Результат преобразования Фурье позволяет не только сжать информацию, но и дает возможность сконцентрироваться на важных аспектах речи, которые интенсивно изучались в сфере экспериментальной фонетики. Пример такого представления см на рис. Спектральное представление достигнуто путем использования широко-частотного анализа записи.
Хотя спектральное представление речи очень полезно, необходимо помнить, что изучаемый сигнал весьма разнообразен. Разнообразие возникает по многим причинам, включая:
-
различия человеческих голосов;
-
уровень речи говорящего;
-
вариации в произношении;
-
нормальное варьирование движения артикуляторов (языка, губ, челюсти, нёба).
Для устранения негативного эффекта влияния варьирования голосового тракта на процесс распознавания речи было использовано множество методов. Первым делом рассматривалась характеристика пространства траектории артикуляторных органов, включая гласные, используемые говорящим. Наиболее удачные формы трансформации, использованной для сокращения различий, были впервые представлены Сакоя & Чибо и назывались динамичными искажениями (dynamic time warping).
Техника динамичного искажения используется для временного вытягивания и сокращения расстояния между искаженным спектральным представлением и шаблоном для говорящего. Использование данной техники дало улучшении точного распознавания (~20-30%).
Метод динамичного искажения используют практически все коммерчески доступные системы распознавания, показывающие высокую точность сообщения при использовании. Техника динамичного искажения представлена на рис.2. Вначале сигнал преобразовывается в спектральное представление, где определяется немногочисленный, но высокоинформативный набор параметров. Затем определяются конечные выходные параметры для варьирования голоса(следует отметить, что данная задача не является тривиальной) и производится нормализация для составления шкалы параметров, а также для определения ситуационного уровня речи. Вышеописанные измененные параметры используются затем для создания шаблона. Шаблон включается в словарь, который характеризует произнесение звуков при передаче информации говорящим, использующим эту систему. Далее в процессе распознавания новых речевых образцов (уже подвергшихся нормализации и получивших свои параметры), эти образцы сравниваются с шаблонами, уже имеющимися в словаре, используя динамичное искажение и похожие метрические измерения. В настоящее время этот метод изучается и дополняется.
Очевидно, что спектральное представление речи позволяет характеризовать особенности голосового тракта человека и способ использования его говорящим. Самый обычный способ моделирования специфических эффектов «модель-источник» — использование фильтров. Речевой аппарат моделируется с использованием источников, вызывающих резонанс, ведущий к пиковым точкам интенсивности звука в соседстве с отдельными частотами, называемыми формантами. При произнесении звуков вибрация голосовых связок является источником возбуждения, и эти короткие импульсы вызывают резонанс между голосовыми связками и губами. Так как язык, челюсть, губы, зубы и альвеолярный аппарат двигаются, размер и место этих резонансов меняются, давая возможность воспроизведения особых параметров звуков.
Возможно построить очень точную модель, также прямо смоделировать движения артикуляторов физиологически реальным путем. Использование этих моделей привели к пониманию пути, в котором происходит речевой сигнал. Но так как наблюдение над артикуляторами затруднено, остаются недостатки. Хотя природа вокального тракта очень сильно влияет на выходной сигнал речи, это не единственное ограничение, которое необходимо принимать во внимание, так как контроль над мускулами звукового тракта обусловлен сигналами моторного кортэкса мозга. Возможно все аспекты влияния акустической структуры контролируют сигналы и форму звукового выхода речи (хотя это не может быть доказано с систематической точки зрения).
Аспекты влияния акустической структуры включает в себя:
-
природу сегментов индивидуального звука (гласные/согласные),
-
слога,
-
морфем (приставки, корни, суффиксы),
-
лексикон,
-
уровень синтаксиса фраз и предложений и
-
долгосрочные ограничения речи (long-term discourse constraints) .
Ниже рассматривается влияние ограничений и способ их воздействия производство сигнала речи. Необходимо также принять во внимание тот факт, что человеческий аппарат восприятия также должен быть смоделирован, он сам по себе накладывает на процесс восприятия дополнительные ограничения. Недавно процесс восприятия был изучен с помощью метода сигнального подавления барабанных перепонок через возбуждение нервных клеток, которые образовывают примерно 30 тысяч нервных окончаний слухового нерва. Но изучение нервных окончаний способно только прояснить формирование простых синтетических гласных. Перед исследователями встало новое главное направление в области изучения воспроизводства речи, связанное с интеграцией всей физиологии восприятия человека. В настоящий момент появляются некоторые модели явлений, происходящих в ухе, и не без оснований можно ожидать дальнейшего улучшения понимания процесса распознавания речи из-за более полного понимания характеристик этого влияния.
Что касается уровня артикуляторного контроля, первым уровнем является индивидуальный фонетический сегмент, иначе говоря, — фонема. Во многих естественных языках их примерно 40. Но их набор существенно различатется. Поэтому, например, английские гласные могут быть носовыми, даже ненамеренно, в то время как во французском носализация гласных является фонетическим контрастом, и поэтому влияют на значение произносимого. Во французском языке носовая коартикуляция доминирует в гласных и существенно влияет на восприятие фонем и следовательно на главный смысл значения. Хотя все говорящие имеют одинаковый голосовой аппарат, использование его разное. Так например, использование кончика языка или прищелкивание, как в некоторых африканских языках. Ясно, что природа артикуляционных движений имеет сильное влияние на метод воспроизведения речи. Эти ограничения всегда активно используются в практических системах.
На следующем уровне лингвистической структуры фонетические сегменты сгруппированы в согласные/гласные, а следовательно и в слоги. Далее, в зависимости от роли фонетического сегмента внутри этих слогов их реализация может быть сильно изменена. Так например, начальный согласный в слоге может быть реализован как абсолютно отличный от конечной позиции. Согласные очень крепко связываются между собой, что опять же влияет на последующие ограничения. Например, в английском если начальная группа согласных состоит из трех фонем, первая фонема должна быть /s/, непроизносимый согласный, третьей или /r/ или /l/, как например, в слове /scrape/ или /split/. Говорящие на родном языке избегают этих ограничений или могут активно их использовать во время процесса восприятия. Из выше приведенных примеров очевидно, что хотя и существуют сильные ограничения, влияющие на слушателя, но их сила не является решающей во время произнесения речи. То есть любое моделирование процесса восприятия может быть активным и может оказать большую помощь в понимании главного смысла.
Другой пример, показывающий необходимость применения сфокусированного поиска, может быть представлен в восприятии конечного согласного. Среди многих ключевых слов для распознавания конечного согласного существует спектральная природа шума, воспроизводимого при освобождении конечной перемычки и перехода резонанса второй форманты в гласный, следующий за этой перемычкой. Многие исследователи изучали эти влияния, и результаты их исследований показали, что ограничивающее влияние обоих вышеописанных характеристик на восприятие варьируется природой следующего гласного, и следовательно, мощная стратегия распознавания должна иметь некоторые знания о твердой позиции гласного перед конечным согласным перед тем, как будет сделано само распознавание конечного согласного. Конечные согласные дают яркий пример весьма интересного комплекса фонетики, используемого для лингвистической окраски. Например, при рассмотрении слов rapid и rabid обнаруживается 16 фонетический различий.
Кроме сегментного и слогового уровней существуют ограниченные влияния из-за структуры морфем, которые являются минимальными синтаксическими единицами языка. Они включают в себя приставки, корни, суффиксы. Можно себе представить, что это синтаксис на слоговом и на морфемном уровнях, также как и нормально распознанный синтаксис, характеризующийся способом, в котором английские слова объединяются во фразы и предложения. Возможно представить данные ограничения как последствия рассмотрения грамматики вне контекста. В этом виде ограничений много “шумных” вариаций сегментов речи, которые так же относятся и к иерархическим синтаксическим ограничениям.
Дополнительные ограничения на природе входа новой лексики в язык могут являться уровнем слова. Многие исследования обнаружили, что характеристика слов при введении разбиения на 5 жестких классов фонетических сегментов может быть сокращена до минимума, часто имея единственное в своем роде распознавание. Далее слишком усиливается эффект порядка двух букв и фонетических сегментов с тех пор как в изучении английских и французских словарей было обнаружено, что более 90% слов имели единственное значение и только 0,5% имели 2 и больше альтернатив. На фонемном уровне было обнаружено, что все слова в английском словаре из 20 тысяч слов имели одно значение из-за беспорядочных фонемных пар. Этот пример помогает показать, что все еще существует ограничивающее влияние на лексическом уровне, которое еще не определено в современных системах распознавания речи. Естественно, что исследования в этой области продолжаются.
Кроме уровня слов синтаксис имеет дополнительное ограничительное влияние. Его влияние на последовательный порядок слов часто характеризуется в системах фактором, который в свою очередь характеризует количество возможных слов, которые могут следовать за предыдущим словом в процессе произнесения. Синтаксис также имеет ограничительные влияния на просодические элементы, такие как ударение, например в случае, когда ударение слов в incline и survey варьируется в зависимости от части речи. Возможно для того, чтобы охарактеризовать ударение в слове, нужно принять во внимание не только индивидуальное слово, но вышеприведенные дополнительные ограничения синтаксиса.
Далее, кроме синтаксического уровня ограничения доминируют над семантикой, прагматикой и речью, что плохо осознается людьми, однако имеет очень важное значение для процесса распознавания.
современные системы влияния,
При другом подходе базы данных и связанные с ними процессы обработки используются Этот подход был изучен системой HEARSAJ 2, которая была разработана в институте Сarnegie-Mellon University, и системой HWIM (hear what I mean).
В этих системах комплексная структура данных, которая содержит всю информацию о воспроизведении звуков, изучается с точки зрения конкретных ограничений. Но как выше указано, каждое из этих ограничений имеет особую внутреннюю модель, и полный анализ не может быть произведен. Для проведения анализа в целом структура данных должна иметь взаимодействие между разными процессами, а также средства для интеграции. Несмотря на то, что структуравключает в себя несколько весьма различных источников знаний и ее вклад в понимание речи очень общий, она также имеет большое количество степеней свободы, которые могут быть использованы для тщательного системного воспроизведения. В отличие от этого, техника, основанная на цепях Маркова, имеет математическую поддержку. Чтобы иметь возможность сфокусированного исследования ограничений взаимодействия и интеграции в контексте, необходимо применять обе системы. Те системы, которые описывают ограничение взаимодействия, сфокусированы во многом на воспроизведении знаний, и они относительно слабо контролируемы, а системам с математической поддержкой, которые в свою очередь имеют великолепную технику для установления параметров и оптимизации изучения, не достает использования комплексной структуры данных, необходимых для характеристики ограничений высокого уровня, таких как синтаксис. Оба направления в настоящий момент находятся в процессе развития.
В заключение следует сделать акцент на влияние производственной технологии на эти системы. Технология интеграции не является большой проблемой для систем распознавания речи, наоборот, это является архитектурой этих систем, включая способ представления ограничений. Необходимо провести грандиозные эксперименты и найти новые способы, которые необходимы для ограничительного влияния взаимодействия.
Во многих способах распознавание речи имеет типичный пример стремительно развивающегося класса высоко интегрированных комплексных систем, которые должны использовать лучшую компьютерную технику и самые последние достижения современного математического обеспечения.
|
4.2 ПРОБЛЕМЫ СОЗДАНИЯ МНОГОУРОВНЕВОЙ СИСТЕМЫ РАСПОЗНАВАНИЯ РЕЧИ |
|
В современных компьютерных системах все больше внимания уделяют построению интерфейса естественным вводом-выводом информации (распознавание рукописного текста, речевой диалог).
Наиболее перспективными на сегодняшний день являются системы речевого ввода. Задачу распознавания речевой информации можно разделить на две большие подзадачи:
Непосредственное распознавание отдельных слов осложняется рядом факторов: различием языков, спецификой произношения, шумами, акцентами, ударениями и т. п. В настоящее время можно выделить два основных направления при построении систем распознавания речи:
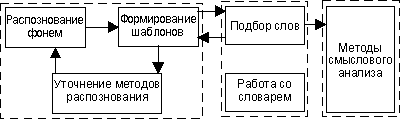
Сравнивая распознавание речевого потока методом распознавания целых слов и распознавание фонем можно сделать вывод: при небольшом количестве слов, используемых оператором более высокую надежность и скорость можно ожидать от распознавания целых слов, но при увеличении словаря скорость резко падает. Предположительно, размер словаря системы распознавания уже в сотню слов делает переход на уровень более низкий, чем распознавание слов в целом, актуальным. Рассмотрим модель построения системы распознавания речи построенной на фонемно-ориектированном методе (Рис.1).
Рис. 1 Построение системы распознавания речи Из списка фонем распознанных с определенной точностью, составляется шаблон, который передается на следующий уровень, где по нему происходит подбор наиболее подходящего слова, передача информации о выборе на более высокий уровень для дальнейшего анализа и на нижний, для подстройки системы на конкретного пользователя. Достоинством этой схемы является высокая адаптивность, дающая возможность динамической самоподстройки системы на оператора, и многоуровневая система проверок, повышающая точность работы. Проанализируем возможные механизмы распознавания фонем. Звуки, участвующие в формировании речи, имеют две основных классификации: по артикуляционным признакам и по акустическим признакам. Классификация звуков по артикуляционным признакам является крайне важным при использовании методов генерации и распознавания речи с помощью моделирования носоглотки, но для решения задач деления на фонемы более интересно рассмотрение акустических различий звуков. По акустическим признакам звуки подразделяются: Тональные звуки — образуются голосом при почти полном отсутствии шумов, что обеспечивает хорошую слышимость звуков: гласные а, э, и, о, у, ы. Сонорные (звучные) — чье качество определяется характером звучания голоса, который играет главную роль в их образовании, а шум участвует в минимальной степени: согласные м, м’, н, н’, л, л’, р, р’. Шумные — их качество определяется характером шума:
Заметим, что гласные и сонорные звуки состоят из участков затухания импульсов от основных (не обертонных) колебаний истинных голосовых связок. Для упрощения, будем называть эти участки доменами. Использование домен при распознавании речи вполне очевидно. По сути, домен (вспомним, что пока домен рассматривается в приложении только к сонорным и гласным звукам) содержит в себе информацию достаточную для распознавания звука. Если взглянуть на образ протяженно произнесенной гласной (или сонорного звука), то за исключением небольших по длине участков в начале и конце образа звук состоит из домен с высокой степенью идентичностью, даже для различных людей многие характеристики, а соответственно и общий вид домен во многом схожи, что придает особую универсальность методам распознавания при выделении и распознавании фонем через домены. Еще одним достоинством домен является относительная простота их выделения. По определению, домен начинается с максимального значения в определенном диапазоне, после которого идет затухающий по некоторому закону колебательный процесс. Как дополнительные условия, которые можно использовать при расчленении речи на домены, можно перечислить:
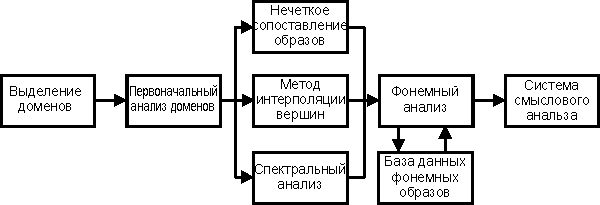
Дополнительно будем рассматривать шумные длительные звуки как один домен. Это позволит легко выделять корень этих звуков из общего потока и облегчит их анализ. Анализ образов шумных мгновенных (взрывных) звуков показывает наличие участков по структуре схожих с определенным для гласных и сонорных звуков понятием домена. Но наряду с совокупностью общих признаков прослеживается различие: для вышесказанных участков в шумных мгновенных звуках отсутствует та строгая идентичность домен между собой. Во всех мгновенных звуках присутствует момент, сильно облегчающий их выделение из речи — перед произнесением таких звуков наблюдается непродолжительная по меркам восприятия, но весьма значительная, в масштабах длительностей домен, пауза. Эго помогает выделению домен. Поэтому в зависимости от различных алгоритмов выделения может быть удобно, разбивать такого рода звуки на несколько домен, или же воспринимать их целиком как один. При разбиении потока речи на домены мы получаем еще один уровень в распознавании. В общей иерархии он находится еще ниже, чем уровень распознавания фонем . Рассмотрим функционирование такой системы (Рис.2).
Рис. 2 Использование доменов в системе распознавания речи Первоначально производится деление потока речи на домены, используя такие свойства доменов как, стабильная длинна на протяжении одной фонемы и большую амплитуду первого колебания в домене. В дальнейшем происходит первичный анализ домена для определения методов его дальнейшей обработки. Эти методы различны для тональных, сонорных и шумных звуков. На втором этапе также производится выделение отдельных слов слитной речи. Подробнее остановимся на методах анализа домен. Целесообразно производить такой анализ в несколько этапов с постепенным уточнением результата:
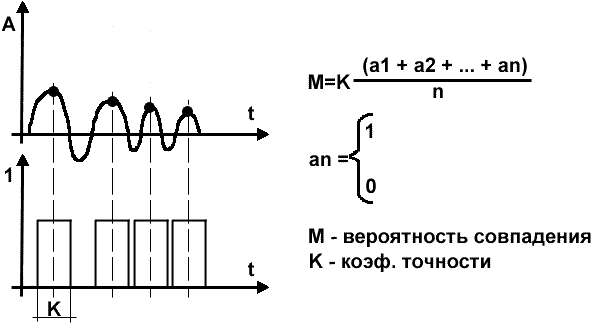
Для этой цели были разработаны несколько методов. Метод нечеткого сопоставления образов при разработке данного метода была использована теория нечеткой логики. Суть метода состоит в следующем: на основе статистических данных составляется двоичный образ доменов для каждой фонемы [1]. Двоичный образ представляет сбой карту локальных выбросов в домене по амплитуде. При этом учитывается лишь местоположение выброса на временном диапазоне, величина амплитуды значения не имеет. Рис.3 Использование функции принадлежности Используя функцию принадлежности можно получить вероятность идентичности анализируемого домена и двоичного образа. Анализ доменов на основе интерполяции вершин. Вид кривой проведенной по вершинам доменов аналогичен для всех доменов данной фонемы и мало различается для различных людей, а также для разных условий произнесения [2]. Первый этап — построение интерполяционного многочлена Тейлора по вершинам домена включает в себя:
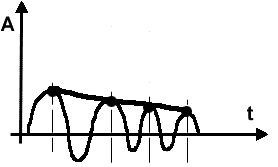
Порядок многочлена задается числом вершин данного домена. Получив функцию, записанную в виде многочлена Тейлора, приступаем к ее анализу (Рис.4).
Рис.4 Интерполяция вершин. Анализ по соотношениям значений функции относительно первого максимума данного домена совместно с анализом по знакам первых производных в наборе точек позволяет оценить общий вид функции и является универсальным, сочетая в себе надежность и гибкость. Используя комбинацию данных методов можно с высокой точностью определить набор фонем для передачи на следующий уровень системы. С каждой фонемой на верхний уровень передается вероятность ее правильного определения. Используя эти данные, формируется набор слов для последующей передачи на уровень смыслового анализа. Предложенная система была частично реализована в опытном программном продукте для анализа свойств доменов и показала свою жизнеспособность. Использование доменов позволит создавать не ресурсоемкие универсальные системы распознавания речи. |
-
ПЕРСПЕКТИВЫ ИСПОЛЬЗОВАНИЯ
Возможности голосового управления открывают перед пользователями огромные перспективы. Если учесть, что сегодня во многих офисах компьютер управляет принтером, модемом, факсом, а с появлением DVD стало возможно подключать к домашнему компьютеру аудиоцентры и домашние кинотеатры, то можно себе представить следующую картину из нашего недалекого будущего. Вы сидите на мягком диване и говорите; «Телевизор», потом — «МузТВ» — включается цепочка «микрофон — звуковая карта — компьютер — телевизор», и вы видите на экране телевизора свой любимый клип. Или вы произносите; «Отправить факс», «номер…», диктуете текст сообщения, потом — «Готово», и через несколько секунд услышите в ответ: «Факс отправлен». И все это вполне реально и осуществимо. Теперь добавьте к этому возможность голосовой навигации по Интернету, распознавание голоса, записанного на любой аудионоситель или в звуковой файл. В общем, пора уже наконец задуматься о приобретении системы распознавания звучащей речи, ведь не за горами тот день, когда вам надо будет только произнести слово!
6. АВТОМОБИЛИ, КОТОРЫМ НЕ НУЖЕН ШОФЁР
Как пожаловался недавно один бывший британский чиновник, самым горьким напоминанием о расставании с должностью служит тот факт, что машина не трогается с места, когда он беззаботно плюхается на заднее сидение.
По мнению самых оптимистичных специалистов по автотранспортным технологиям, неприятности такого рода могут через некоторое время сойти на нет. Пройдет десяток — другой лет, и автомобилисты 21-го века будут с уютом располагаться на задних сидениях машин и небрежно отдавать приказ: «Домой!».
Многие технологии, позволяющие автомобилю управлять своим движением, появляются уже сейчас. Системы спутниковой навигации уже присутствуют на рынке. Средства избежания столкновений, с компьютерным управлением мотором, тормозами и рулевой частью, скоро увидят свет.
Еще три года назад гоночные машины Формула-1 наделялись средствами автоматического передвижения по трассе, но такая «электронная» гонка была запрещена спортивными регулирующими органами. Препятствия на пути реализации идеи самоуправляющегося автомобиля лежат как в технологической области, так и в сфере закона.
Возможность давать автомобилю указания о маршруте станет, в конечном итоге, закономерным результатом развития и внедрения систем распознавания речи. Пока они все в большей степени используются для менее глобальных нужд, в том числе для контроля водителя за отдельными элементами машины.
Технология распознавания речи все еще находится на одном из начальных этапов развития. Тем не менее ведущие производители автомобилей и их компонентов очень высоко оценивают ее потенциал и значимость.
Если ранее эта технология рассматривалась лишь как средство указания номера сотовому телефону без использования рук, то теперь речевые команды расширили сферу своего влияния и на другие
Так, система распознавания речи CD-VC50 производства компании Pioneer, подключенная к автомобильному проигрывателю компакт-дисков, позволяет водителю, нажав кнопку, назвать имя певца, которого он хочет послушать. Эта система, содержащая скрытый интерфейсный блок, блок дистанционного управления и небольшой микрофон, продается в Великобритании примерно за 400 дол. или за 800 дол. — в комплекте с проигрывателем Pioneer CDX-P5000.
Другие производители аппаратуры также намерены использовать технологию распознавания речи. Она привлекает и потребителей, и изготовителей тем, что повышает безопасность движения, освобождая руки водителей для более полного контроля за рулем.
Этими же соображениями руководствовались сотрудники Visteon, отделения компании Ford, создавшие систему распознавания речи, предназначенную для выполнения целого ряда функций в автомобилях Ford и других фирм. Система Visteon VACS (voice-activated control system) должна появиться в промышленных вариантах автомобилей в следующем году.
Водителей, оценивших преимущества систем спутниковой навигации, VACS избавит от необходимости перед поездкой вручную вводить информацию о пункте назначения. Чтобы убедить водителя в правильности интерпретации его слов, VACS «вслух» сообщает о получении тех или иных инструкций с помощью синтезатора речи.
VACS не требуется «изучать» особенности речи пользователя. По сведениям создателей, она полностью «независима от говорящего» и воспринимает множество языков и диалектов.
В этом году появятся первые BMW с речевым управлением аудио- и телефонной аппаратурой. Но это только начало. За три года инженеры BMW намерены научить системы распознавания и воспроизведения речи автомобильных компьютеров «обсуждать» с водителем варианты маршрута. При этом будет использоваться спутниковая навигационная система CARIN. Когда компьютер не будет занят распознаванием диктуемого текста, чтением сообщений электронной почты или факсов, он сможет передавать или получать информацию по модему, установленному в автомашине. BMW сообщает, что не все возможности автоматического управления будут непременно реализованы. Машину можно научить реагировать на отдельные речевые команды, например, «Левый поворот», создав систему дублирования рулевого управления. Представители фирмы считают, что недостатки идеи не сводятся к возможным проблемам правового характера в случае сбоев таких систем или их неправильного использования: «Главное, мы потеряем удовольствие от вождения.»
Компания Ford уже заключила с Intel и Microsoft соглашения об интеграции подобных функций в автомобильные мультимедиа-системы ICES (information, communication, entertainment, safety and security) на базе Windows.
General Motors оснастила некоторые свои модели системой OnStar, с помощью которой водители могут обращаться в центры службы поддержки движения, используя речевой интерфейс.
В дорогих автомобилях типа Infinity и Jaguar уже несколько лет используется устный контроль за панелью управления: радио, температурный режим и навигационная система понимают голос владельца машины и беспрекословно слушаются хозяина. Но сейчас технология распознавания голоса начинает применяться и в машинах среднего класса. Так, с 2003-года Honda Accord имеет встроенный голосовой определитель от IBM. Он называется ViaVoice и является частью навигационной системы за 2000 долл. По сообщению компании-поставщика, одна пятая часть покупателей Honda Accord сделала выбор в пользу модели с голосовой системой навигации.
ЗАКЛЮЧЕНИЕ
Технологии распознавания речи считаются одними из наиболее перспективных в мире. Так, по прогнозам американской исследовательской компании Cahners In-Stat, мировой рынок ПО распознавания речи к 2005 году увеличится с 200 млн. до 2,7 млрд. долл. По мнению же фирмы Datamonitor, объем рынка голосовых технологий будет расти в среднем на 43% в год: с 650 млн. долл. в 2000 году до 5,6 млрд. долл. в 2006-м (рис. 5).
Эксперты, сотрудничающие с медиа-корпорацией CNN, отнесли распознавание речи к одной из восьми наиболее перспективных технологий нынешнего года. А аналитики из IDC заявляют, что к 2005 году распознавание речи вообще вытеснит с рынка все остальные речевые технологии (рис. 6).
По мере развития компьютерных систем становится все более очевидным, что использование этих систем намного расширится, если станет возможным использование человеческой речи при работе непосредственно с компьютером, и в частности станет возможным управление машиной обычным голосом в реальном времени, а также ввод и вывод информации в виде обычной человеческой речи.
|
2000 2001 2002 2003 2004 2005 Годы Рис. 5. Рост рынка речевых технологий, по данным IDC и Datamonitor (верхняя кривая) |
3.1% —озвучивание текстовой информации 0,7% — идентификация по голосу 96.2% — авотоматическое распознавание речи Рис. 6. Структура рынка речевых технологии к 2005 году (по данным IDC) |

Список использованной литературы:
[Электронный ресурс]//URL: https://inzhpro.ru/referat/tehnologiya-raspoznavaniya-zvukov/
-
Компьютер – пресс, сентябрь 2004, стр. 28-32.
-
Компьютер – пресс, июль 2003, стр. 63-68.
-
http://alife-soft.narod.ru/note/s_recognize/recognize.html