
Для преобразования программы, представленной на одном из языков программирования, в программу на другом языке и, в определенном смысле, равносильную первой существуют специальные программы — трансляторы.
Трансляторы делятся на интерпретаторы и компиляторы. Интерпретаторы исполняют программу сразу же в зависимости от реализации построчно или целиком после предварительного анализа. Компиляторы преобразуют программы в машинный язык, принимаемый и исполняемый непосредственно процессором. Некоторые компиляторы способны вести себя как интерпретаторы, компилирую программу непосредственно в память.
Следует также отметить, что крайне важной частью процесса трансляции является точная диагностика ошибок, допущенных во входной программе.
Задачей данной курсовой работы является проектирование, и реализация анализирующей части компилятора языка С++. Язык реализации С++.
Базовые требования к реализации компилятора, на удовлетворение которых должны быть направлены решения:
- полнота и конформность стандарту языка — реализация должна поддерживать все свойства языка С++, определенные в стандарте, и обеспечивать полное соответствие стандарту;
- универсальность — реализация должна обеспечивать необходимую общность с тем, чтобы поддерживать не только задачи трансляции, но и целый ряд других операций над текстами С++ (анализ программ, извлечение семантической информации и т.д.);
- эффективность — реализация должна обеспечивать производительность, сравнимую с современными промышленными компиляторами С++.
компилятора
Процесс компиляции состоит из следующих этапов.
1. Лексический анализ. На этом этапе последовательность символов исходного файла преобразуется в последовательность лексем.
2. Синтаксический (грамматический) анализ. Последовательность лексем преобразуется в дерево разбора.
— Семантический анализ. Дерево разбора обрабатывается с целью установления его семантики (смысла) — например, привязка идентификаторов к их декларациям, типам, проверка совместимости, определение типов выражений и т. д. Результат обычно называется «промежуточным представлением/кодом», и может быть дополненным деревом разбора, новым деревом, абстрактным набором команд или чем-то ещё, удобным для дальнейшей обработки.
- Оптимизация. Выполняется удаление излишних конструкций и упрощение кода с сохранением его смысла. Оптимизация может быть на разных уровнях и этапах — например, над промежуточным кодом или над конечным машинным кодом.
- Генерация кода. Из промежуточного представления порождается код на целевом языке.
Лексический анализ — первая фаза компиляции. На этом этапе исходный текст программы на транслируемом языке преобразовывается в последовательность лексем, принадлежащих различным лексическим классам. В таком виде синтаксический анализатор получает исходную программу.
Бухгалтерский учет и анализ производства и реализации продукции
... ее распределения. Цель курсовой работы состоит в подробном рассмотрении учета и анализа производства и реализация продукции предприятия. Предмет исследования - производство и реализация продукции предприятия. Задачи ... последовательности определенные этапы производства - процессы, пока не будут полностью завершены. Попередельный метод заключается в том, что затраты на весь цикл производства, ...
Помимо этого лексический анализатор может решать и другие задачи, такие как:
- отбрасывание пробельных символов и комментариев (пробел, символы табуляции и новой строки, а также, возможно, некоторые другие символы, использующиеся для отделения токенов друг от друга во входном потоке);
- синхронизация сообщений об ошибках с исходным текстом программ (лексический анализатор может отслеживать количество символов новой строки, чтобы каждое сообщение об ошибке сопровождалось номером строки, в которой она обнаружена);
- Существует несколько способов реализации лексического анализа: конечные автоматы или генераторы лексических анализаторов (lex, Flex, gplex, OOlex).
Для реализации был выбран непрямой лексический анализатор на основе диаграмм переходов.
Непрямой лексический анализатор реализуется как совокупность независимых конечных автоматов, проверяющих принадлежность к отдельным лексемам, автоматы можно описать с использованием диаграмм Вирта.
Каждый автомат представлен соответствующей функцией, осуществляющей имитацию переходов от начального состояния к одному из заключительных.
Принципы программной реализации:
- каждому состоянию ставится в соответствии метка;
- анализируемые альтернативы проверяются условными операторами;
- если результат проверки является истиной, проводится обработка контекста, берется следующий символ и осуществляется переход на новую метку (в новое состояние);
- процесс повторяется до тех пор, пока не произойдет переход в одно из заключительных состояний.
компилятор алгоритм синтаксический анализатор
Алгоритм работы лексического анализатора
В программе лексемы разделены на классы: ключевые слова, операторы, пунктуаторы, символы, скобки, числа.
Описание класса:
class KeyWord
{ private:
- list<AnsiString>
- keyword;
- //список ключевых слов
public:();operator ()(const AnsiString s); //проверяет принадлежность к списку
};
- Входные данные помещаются в массив vector<struct symbol>
- sym_table (посимвольно).
Структура symbol передает символ, строку, столбец, длину символа и позицию от начала.
Выходные данные формируются в массиве vector<struct cell> scaner_result. описание типа, саму лексему, строку, столбец, длину лексемы и позицию от начала.
Символ из массива sym_table проверяется на принадлежность к определенному классу лексем, если функция возвращает значение истина, то символ переписывается в переменную curr_cell (объект структуры cell) и переходим к следующему символу, так же проверяем на принадлежность к этому же классу лексем, если функция возвращает значение ложь, то записываем данные из переменной curr_cell в массив scanner_result, обнуляем переменную curr_cell, проверяем если ли в массиве sym_table еще символы, если он не пустой, то переходим к следующему.
Анализаторы газов и жидкостей
... анализаторы жидкости потенциометрические; анализаторы жидкости - солемеры; анализаторы жидкости амперометрические; анализаторы жидкости кулонометрические; анализаторы жидкости полярографические; анализаторы жидкости механические, звуковые и ультразвуковые; анализаторы жидкости гидромеханические; анализаторы жидкости ротационные; анализаторы жидкости вибрационные; анализаторы жидкости звуковые и ...
Данные об ошибках хранятся в массиве error_result.
Как только массив sym_table оказался пуст, данные из массивов scanner_result и error_result выводятся в таблицы.
Исходный код программы, выбранной для разбора, представлен в Приложении А. Результат разбора кода лексическим анализатором представлен на рисунке 1.
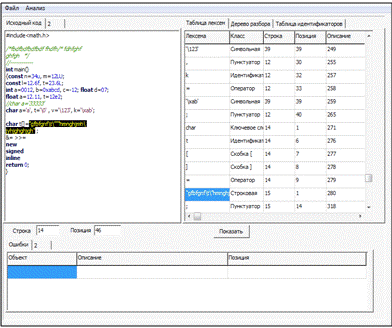
Рисунок 1 — Результат работы лексического анализатора
В фазе лексического анализа возможны следующие ошибки — не закрыт комментарий, незавершенная строка, ошибка в определении вещественной константы, ошибка в определении символьной константы.
Так «область видимости» лексического анализатора узка, то без помощи других компонентов компилятора ему достаточно сложно обнаружить ошибки в исходном тексте программы, например, если в программе токен F впервые встретился в контексте F=a*33. Поскольку F является корректной лексемой, лексический анализатор должен вернуть этот токен синтаксическому анализатору, который в свою очередь должен обработать ошибку «Неопределенный тип».
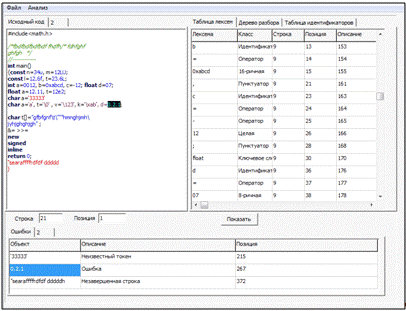
Рисунок 2 — Результат работы лексического анализатора с найденными ошибками
Полученная последовательность токенов, записанная в массив scaner_result передается синтаксическому анализатору. Компилятор переходит к следующей фазе.
Синтаксический анализ — вторая фаза компиляции. На этом этапе программа работает с последовательностью токенов, созданной лексическим анализатором. Синтаксический анализатор, или парсер, должен проверить корректность последовательности токенов для транслируемого языка и на выходе должно получиться промежуточное представление программы.
Также от синтаксического анализатора ожидаются сообщения обо всех выявленных ошибках. В случае корректной программы синтаксический анализатор строит дерево разбора и передает его следующей части компилятора для дальнейшей обработки.
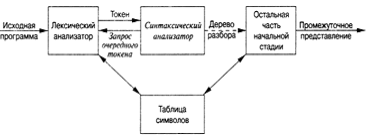
Рисунок 3 — Место синтаксического анализатора в модели компилятора
Существуют различные формы промежуточного представления программы, например, троичный код или абстрактное синтаксическое дерево. В данном случае используется абстрактное синтаксическое дерево.
Методы, обычно применяемые в компиляторах, можно классифицировать как нисходящие (сверху вниз — top-down) или восходящие (снизу вверх — bottom-up).
Как следует из названий, нисходящие синтаксические анализаторы строят дерево разбора от корня и листьям, тогда как восходящие начинают с листьев и идут к корню. В обоих случаях входной поток синтаксического анализатора сканируется посимвольно слева направо.
Экспрессивные синтаксические конструкции
... есть экспрессивными конструкциями. Объект исследования - экспрессивные синтаксические конструкции в современных публицистических текстах. Предмет исследования -- функционирование экспрессивных синтаксических конструкций в ... факты». Цель исследования состоит в комплексном анализе экспрессивных синтаксических конструкций, содержащихся в публицистических текстах. 1. Лингвистическая категория ...
Наиболее эффективные нисходящие и восходящие методы работают только с подклассами грамматик, однако некоторые из этих классов, такие как LL- и LR-грамматики, достаточно выразительны для описания основных синтаксических конструкций языков программирования. Реализованные вручную синтаксические анализаторы чаще работают с LL-грамматиками; например, предикативный подход работает с LL-грамматиками. Синтаксические анализаторы для большего класса LR-грамматик обычно создаются с помощью автоматизированных инструментов.
Выходом синтаксического анализатора является некоторое представление дерева разбора потока токенов от лексического анализатора. На практике имеется множество задач, которые могут сопровождать процесс разбора, такие как сбор информации о различных токенах в таблицу символов, выполнение проверки типов и других видов семантического анализа, а также генерация промежуточного кода.
Алгоритм работы синтаксического анализатора
Создана структура TLexeme, переменная curr_par типа cell, в нее записываются данные из массива, который передает лексический анализатор. Из переменной curr_cell данные переписываются в массив Lexemes. Дальше работаем только с массивом Lexemes.
struct TLexeme
{ String type; //тип токенаbody; //сам токенposition; //строка
};
- Lexemes;
- // Найденные лексемы: тип, тело, строкаcurr_par;
- //объект структуры (сама структура в 1.h)
int Number = Form1->scaner_result.size(); //передаем количество лексем= new TLexeme [Number]; //нейденные лексемы(int i=0, j=0; i<Number; i++)
{ //в «строку» перемещаем данные из БОЛЬШОГО массива
curr_par=Form1->scaner_result[j];
//сразу записываем в новый
Lexemes[j].type=curr_par.type;
- Lexemes[j].body=curr_par.value;[j].position=curr_par.str;++;
}
Дальше по циклу проверяем принадлежность лексемы к какой-либо синтаксической конструкции.
if (Lexemes[i].body==»struct»)
{ add_tabs(dest,tabs);<<«struct»<<‘\n’;++; i++;(Lexemes[i].type==»Идентификатор»)
{ add_tabs(dest,tabs);<<«Имя»<<‘\n’;++;_tabs(dest,tabs);<<Lexemes[i].body.c_str()<<‘\n’;++; tabs—;
- }_tabs(dest,tabs);<<«{}»<<‘\n’;(Lexemes[i].body==»{«)
{ //i++;
- i=MakeBinTree(dest,tabs,tabs,i,1,»@#$%^&(«,tecFN);
- //вызов рекурсии для того, что в {}++;
- //tabs—;
- }(Lexemes[i].type==»Идентификатор») //18:48 добавила условие, чтобы выводились объекты структуры
{ while (Lexemes[i].type==»Идентификатор» || Lexemes[i].body==»,»)
{ if (Lexemes[i].type==»Идентификатор»)
{ add_tabs(dest,tabs);<<Lexemes[i].body.c_str()<<‘\n’;
- }++;
}
}-;
}
Изначально дерево записывается в текстовый файл, как только программа анализирует весь массив, данные из текстового файла загружаются в объект TreeView.
Для записи объекта в текстовый файл используется функция add_tabs.
Разработка Web-представительства
... 1.2 Экономическая сущность задачи Экономической сущностью задачи «Разработка Web-представительства» является цель создания данной разработки. В нашем случае целью является увеличение реализации продукции, ... Технико-экономическая характеристика предметной области В данной курсовой работе мы создали Web-представительство компании по производству металлопластиковых, алюминиевых, деревянных окон “Super ...
void add_tabs(ofstream &dest,int tabs)
{ //передаю уровень, иду по циклу ставлю табуляцию
for(int j=0;j<tabs;j++)
dest<<‘\t’;
}
В результате разбора строится синтаксическое дерево Рисунок 4.
Синтаксические ошибки включают неверно поставленные точки с запятой или лишние недостающие скобки, отсутствие условий (для оператора while), отсутствие тела (switch, while, do while), неверное количесво параметров (for), неопределенный тип (если переменная не была объявлена).
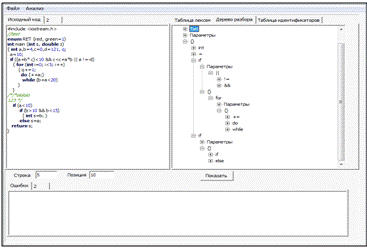
Рисунок 4 — Результат работы синтаксического анализатора
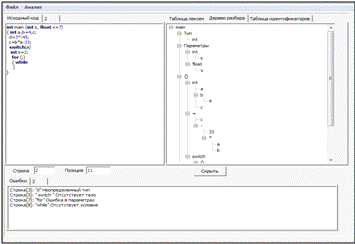
Рисунок 5 — Результат работы синтаксического анализатора с найденными ошибками
Семантический анализ — третья фаза компиляции. Так как на этапе синтаксического анализа нет достаточной информации о типах, парсер проверяет лишь формальную корректность последовательности токенов. Задача семантического анализа состоит в том, чтобы сконструировать пользовательские типы и проконтролировать соответствие типов в программе. В случае, когда типы не совпадают, но возможно неявное приведение, семантический анализатор должен встроить функции приведения типов в абстрактное синтаксическое дерево, полученное на входе.
Так как по факту выполняется не что иное, как обход дерева, семантический анализ реализуется набором рекурсивных функций для обхода блоков, абстрактного синтаксического дерева и для проверки корректности типа данных «Запись», так как он тоже имеет древовидную структуру.
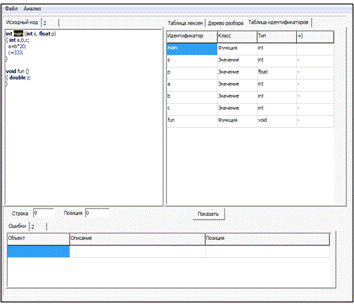
Рисунок 6 — Построение таблицы идентификаторов
В данной курсовой работе были реализованы следующие фазы компиляции:
1) лексический анализ результатом, которого является таблица токенов;
2) синтаксический анализ результатом, которого может быть дерево разбора в случае корректности анализируемого кода;
- построена таблица идентификаторов.
Реализованное приложение позволяет анализировать файлы с расширением и *.cpp, *.h, *.c, *.hpp.
Для реализации компилятора был выбран не самый оптимальный метод, т.к. уже существует множество различных генераторы лексического и синтаксического анализа, использование которых позволяет сократить время и повысить эффективность.
1. Ахо, Лам, Сети, Ульман. Компиляторы: принципы, технологии и инструментарий, 2-е изд.: Пер. с англ. — М.: ООО «И.Д. Вильямс», 2008. — 1184 с.: ил.
2. Мозговой М. В. Классика программирования: алгоритмы, языки, автоматы, компиляторы. Практический подход. — СПб.: Наука и Техника, 2006. — 320 с.: ил.
- Серебряков В.А., Галочкин М.П. Основы конструирования компиляторов, Москва, 2001. — 224с.
Текст тестовой программы для проверки корректности работы лексического анализатора
Кисель элана вадимовна использование технологии для получения мутантов по
... В связи с ограничениями использования случайного мутагенеза и развитием молекулярно-генетических технологий для генетических манипуляций с данио начали использовать и другие методики: ... полученных после микроинъекций особей. 1. Обзор литературы [Электронный ресурс]//URL: https://inzhpro.ru/diplomnaya/tehnologiya-crispr/ 1.1. Danio rerio как модельный объект для генетических манипуляций Danio rerio ...
#include<math.h>
/*fbdfbdfbdfbdf fhdfh/* fdhfghf*/
//————main()
{const n=34u, m=12LU;l=12.6f, t=23.6L;u=11e-10f;a=0012, b=0xabcd, c=-12; float d=07;
- a=12.11, t=12e2, u=-0.23e-12;
- a=’a’, t=’\0′ , v=’\123′, k=’\xab’;
- t[]=»gfbfgnf\t\»»»hmnghjmh\» ;
- &=
>>=0;
}
Текст тестовой программы для проверки корректности работы синтаксического анализатора
#include <iostream.h>
//testRET {red, green=1}main (int s, double z)
{ int a,b=4,c=0,d=121, q;=10;((a+b* c)<10 && c<c+a*b || a !=-d)
{ for (int i=0; i<5; i++)
{ q+=1;{++a;}(b+a<20)
}
}
/*/*olololo
*/(a<10)(b>10 && b<15)
{ int s=b; }s=a; s;
}
//———————
Хранение лексем
bool Punkt::operator() (const AnsiString s)
{ return find(punkt.begin(),punkt.end(),s)!=punkt.end();
}::Punkt()
{ punkt.push_back(«…»); punkt.push_back(«;»);.push_back(«:»); punkt.push_back(«,»);
- if (ISpunkt(sym_table[i].chr))
{ int len=0;_cell.str=sym_table[i].str;_cell.sym=sym_table[i].sym;_cell.pos=pos;=»»;{curr+=sym_table[i++].chr; len++; pos++;}(ISpunkt(sym_table[i].chr));(ISpunkt(curr))_cell.type=»Пунктуатор»;_cell.value=curr;_cell.len=len;.push_back(curr_cell);—;
- continue;
}
Функция проверяет на наличие арифметических операций в выражении
int if_there_arifmetic_ops(long ii)
{ TLexeme* Lexemes; // Найденные лексемы: тип, тело, строка
cell curr_par; //объект структуры (сама структура в 1.h)
int Number=Form1->scaner_result.size();= new TLexeme [Number]; //нейденные лексемы(int t=0, j=0; t<Number; t++)
{ //в «строку» перемещаем данные из БОЛЬШОГО массива
curr_par=Form1->scaner_result[j];
//сразу записываем в новый
Lexemes[j].type=curr_par.type;
- Lexemes[j].body=curr_par.value;[j].position=curr_par.str;++;
- }f=0;i;cs=0;//Счет скобок(i=ii;i<Number;i++)
{ if(Lexemes[i].body==»;» || Lexemes[i].body==»,» ) break;(Lexemes[i].body==»&&» || Lexemes[i].body==»||» || Lexemes[i].body==»<» || Lexemes[i].body==»>»
|| Lexemes[i].body==»!=» || Lexemes[i].body==»==» || Lexemes[i].body==»<=» || Lexemes[i].body==»>=») break;(Lexemes[i].body==»(«) cs++;(Lexemes[i].body==»)») cs—;(cs<0) break;(Lexemes[i].body==»+» || Lexemes[i].body==»-» || Lexemes[i].body==»*» || Lexemes[i].body==»/» || Lexemes[i].body==»^»)=1;
- }f;[]Lexemes;
}