Интернет — это глобальная компьютерная сеть, в которой размещены различные службы или сервисы (E-mail, Word Wide Web, FTP, Usenet, Telnet и т.д.).
Компьютерные сети предназначены для передачи данных, а телефонные сети и радиосети — для передачи голоса, телевизионные сети — для передачи изображения[1].
В зависимости от расстояний между ПК различают локальные, территориальные и корпоративные вычислительные сети. Конвергенция телекоммуникационных сетей (компьютерных, радио, телефонных и телевизионных сетей) обеспечивает возможность качественной передачи данных, голоса и изображения по единым (мультисервисным) сетям нового поколения (сетям Internet)[7].
Интернет давно уже стал не только средством общения, но и полем для серьезной коммерческой деятельности. Практически каждая зарубежная фирма имеет в Сети свое представительство, виртуальный офис. Суммарный оборот компаний, ведущих торговлю в Интернет, достигает миллиардов долларов. В России также все большее число компаний использует Интернет для продвижения своих товаров и услуг. В этом легко убедиться, просмотрев рекламные издания. Рядом с привычными номерами телефонов и факсов все чаще и чаще встречаются адреса электронной почты и Web-сайтов. Скоро отсутствие адреса в Интернет будет затруднять работу так же, как отсутствие факса.
Поэтому все больше и больше людей обращаются в Интернет, чтобы получить самую свежую информацию: об услугах и ценах, погоде, курсах валют, просто новости. На Web-сайте можно менять информацию несколько раз в день. В печатных изданиях надо заказывать рекламу минимум за неделю, а то и больше. А в Интернет все оперативно: новые товары или услуги, новая скидка или новый поставщик — завтра об этом узнают клиенты. Нет необходимости ждать, пока выйдет очередной выпуск печатной рекламы. Информация на сайте будет всегда актуальной, самой свежей. Именно это ценят, именно это привлекает в Интернет миллионы пользователей[4].
Важнейшим условием и ведущим фактором, определяющим успешность учебной деятельности с использованием компьютерных технологий, является готовность учащихся к продуктивной деятельности в дидактической компьютерной среде.
Большинство исследователей в области педагогической информатики отмечают существование противоречия между представлениями современной гуманитарно-личностной парадигмы образования и существующей системой обучения с узкопредметной ориентацией, не обеспечивающей готовность учащегося к учебной деятельности с использованием компьютерных методов получения и преобразования информации. Становится очевидным, что концепции использования в учебном процессе информационных технологий эволюционируют от технократических парадигм в направлении усиления роли социокультурных факторов, учета нравственного и интеллектуального потенциала личности.
Разработка интернет-магазина по продаже компьютерной техники
... данного дипломного проекта необходимо разработать сайт интернет-магазина по продаже компьютерной техники. В нем должен быть необходимый перечень ... типами WEB-браузеров. Когда документ создан с использованием HTML, WEB-браузер может интерпретировать HTML для ... информация используется для их идентификации между сеансами работы с интернет-магазином. Данная информация может храниться как на стороне ...
Овладение эффективными методами и средствами поиска, обработки и использования учебной информации дает возможность не только интенсифицировать образовательные процессы, но и развивать познавательные интересы учащихся, стремление к продуктивной, творческой деятельности[1].
Цель курсовой работы:
Исследовать существующие системы и механизмы поиска информации в сети.
Задачи курсовой работы:
1. Изучить соответствующую данной теме специализированную литературу.
- На основе полученных из данной литературы знаний, выяснить каким образом устроены процессы хранения и поиска информации в глобальной сети
- Найти сходства и различия поисковых машин.
1.
Основные понятия информационного поиска
Информационно-поисковая система
В зависимости от объекта хранения и типа запроса различают два вида информационного поиска: документальный и фактографический — и, соответственно, два типа ИПС — документальные и фактографические.
Документальными
Фактографические
Главное, различие между документальным и фактографическим поиском заключается в подходе к семантике документов. В документальных системах описывается смысл документов в целом с точки зрения их тематического, предметного содержания. В этом случае важно выявить и назвать (перечислить) основные темы и объекты, которым посвящен документ. В фактографических системах описываются объекты, фиксируются их признаки и значения этих признаков. Отсюда различия в языках описания и способах хранения описаний в системе. Соответственно, для каждого вида поиска существуют свои поисковые средства.
Фактографические системы предполагают накопление и поиск в массиве документов со строго регламентированной структурой. Такая структура является или результатом предварительной интеллектуальной обработки документов при вводе информации в систему, или наличием таких документов в готовом виде в конкретных сферах человеческой деятельности, например, учетные формы, бланки, справочники, расписания и т.п. Существуют фактографические ИПС, которые обеспечивают накопление информации и поиск только по одному типу объектов и только по одному типу запросов. Существуют и более развитые фактографические системы, обеспечивающие хранение и поиск данных, разнообразных по содержанию и структуре, но это разнообразие всегда конечно.
В то же время между документальными и фактографическими системами нет непреодолимой разницы. Нередко реальные ИПС представляют собой пример смешанных систем, в которых фактографическая информация используется как дополнительное средство документального поиска, и наоборот. В документальных системах тексты (документы) также могут быть структурированы, разбиты на фрагменты или поля, и обработка и выдача документальной информации может вестись на уровне отдельных полей.
Выделяют еще и третий тип систем, которые называют информационно-логическими. Это системы, отвечающие на запросы, на которые в информационной базе в явном виде ответа нет. Получить ответ помогает экстралингвистическая база знаний и информация, порождаемая алгоритмически из уже имеющейся (документальной или фактографической).
Проектирование локальной вычислительной сети управления систем ...
... и эксплуатации сети важными требованиями при работе сети являются следующие: 1. производительность – это характеристика сети, позволяющая оценить, насколько быстро информация ... в различных автоматизированных системах управления, производящих обработку информации и управление процессами в ... и играм, однако в последнее время намечается тенденция «взросления» запросов, когда поиск справочной информации ...
Эта новая информация или выдается как ответ на запрос, или дополнительно используется для поиска.
Информационно-поисковая система документального типа представляет собой упорядоченную совокупность документов, а также совокупность средств и методов, предназначенных для хранения, поиска и выдачи по запросам документальной информации. Документальная ИПС выдает документы, соответствующие запросу по теме, по предмету.
большинство работающих ИПС относится к классу вербальных систем бестезаурусного типа, когда индексационные термины выбираются непосредственно из текстов документов. Лавинообразный рост объемов электронной документальной информации, ее видовое, тематическое и языковое разнообразие являются как причиной кризиса современного информационного поиска, так и стимулом его совершенствования.
Проблема поиска ресурсов в сети Интернет была осознана достаточно скоро, и в ответ появились различные системы и программные инструменты для поиска, среди которых следует назвать системы Gopher, Archie, Veronica, WAIS, WHOIS и др. В последнее время на смену этим инструментам пришли «клиенты» и «серверы» всемирной паутины WWW.
Если попытаться дать классификацию ИПС сети Интернет, то можно выделить
- ИПС вербального типа (поисковые системы — search engines)
- Классификационные ИПС (каталоги — directories)
- Электронные справочники («желтые» страницы и т.п.)
- Специализированные ИПС по отдельным видам ресурсов
- Интеллектуальные агенты.
Глобальный учет всех ресурсов Интернета обеспечивается вербальными и отчасти классификационными системами. [1]
2. Инфраструктура сети (структура и принципы построения сети Интернет)
— всемирная информационная компьютерная сеть, представляющая собой объединение множества региональных компьютерных сетей и компьютеров, обменивающих друг с другом информацией по каналам общественных телекоммуникаций (выделенным телефонным аналоговым и цифровым линиям, оптическим каналам связи и радиоканалам, в том числе спутниковым линиям связи).
Информация в Internet хранится на серверах. Серверы имеют свои адреса и управляются специализированными программами. Они позволяют пересылать почту и файлы, производить поиск в базах данных и выполнять другие задачи.
Обмен информацией между серверами сети выполняется по высокоскоростным каналам связи (выделенным телефонным линиям, оптоволоконным и спутниковым каналам связи).
Доступ отдельных пользователей к информационным ресурсам Internet обычно осуществляется через провайдера или корпоративную сеть.
Провайдер — поставщик сетевых услуг — лицо или организация предоставляющие услуги по подключению к компьютерным сетям. В качестве провайдера выступает некоторая организация, имеющая модемный пул для соединения с клиентами и выхода во всемирную сеть[9].
Основными ячейками глобальной сети являются локальные вычислительные сети. Если некоторая локальная сеть непосредственно подключена к глобальной, то и каждая рабочая станция этой сети может быть подключена к ней. Существуют также компьютеры, которые непосредственно подключены к глобальной сети. Они называются хост — компьютерами (host — хозяин).
Особенности сети Интернет как средства распространения информации
... миллионы пользователей. 1. Интернет как средство информации 1.1 Понятие Интернет как СМИ. Средство массовой информации -- средство распространения информации, характеризующееся: обращенностью к массовой аудитории, общедоступностью, корпоративным характером производства и распространения информации. К средствам массовой информации относятся: пресса,радио,телевидение; кинематограф,звукозаписи ...
Хост — это любой компьютер, являющийся постоянной частью Internet, т.е. соединенный по Internet — протоколу с другим хостом, который в свою очередь, соединен с другим, и так далее.
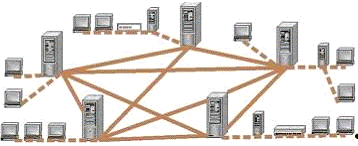
Рис. 1. Структура глобальной сети Internet
Для подсоединения линий связи к компьютерам используются специальные электронные устройства, которые называются сетевыми платами, сетевыми адаптерами, модемами и т.д.[7].
Практически все услуги Internet построены на принципе клиент-сервер. Вся информация в Интернет хранится на серверах. Обмен информацией между серверами осуществляется по высокоскоростным каналам связи или магистралям. Серверы, объединенные высокоскоростными магистралями, составляют базовую часть сети Интернет.
Передача информации в Интернет обеспечивается благодаря тому, что каждый компьютер в сети имеет уникальный адрес (IP-адрес), а сетевые протоколы обеспечивают взаимодействие разнотипных компьютеров, работающих под управлением различных операционных систем.
В основном в Интернет используется семейство сетевых протоколов (стек) TCP/IP. На канальном и физическом уровне стек TCP/IP поддерживает технологию Ethernet, FDDI и другие технологии. Основой семейство протоколов TCP/IP является сетевой уровень, представленный протоколом IP, а также различными протоколами маршрутизации. Этот уровень обеспечивает перемещение пакетов в сети и управляет их машрутизацией. Размер пакета, параметры передачи, контроль целостности осуществляется на транспортном уровне TCP.
Прикладной уровень объединяет все службы, которые система предоставляет пользователю. К основным прикладным протоколам относятся: протокол удаленного доступа telnet, протокол передачи файлов FTP, протокол передачи гипертекста HTTP, протоколы электронной почты: SMTP, POP, IMAP, MIME[10].
3. История появления поисковых систем, Сравнительный обзор поисковых систем
С развитием Интернет в мире, на первое место вышла проблема поиска информации в сети. Эту нишу сразу попытались занять несколько различных крупных фирм, таких как Altavista, Lycos, AOL. Естественно, что каждая из них разработала свои собственные методы для нахождения информации. Это и ручной метод в каталогах, и метод автоматического поиска сайтов в Интернет, и индексации их при помощи специально разработанных для этого «spider»-ов. Их целью было, начиная с нескольких крупных web-узлов, по имеющимся на них ссылкам, группам новостей, проиндексировать весь интернет. Но поскольку, ждать пока такой спайдер доберется до вашего сайта, приходилось очень долго, было принято решение о ручном добавлении сторонними web-мастерами к базе спайдера ссылок, следуя по которым спайдер мог быстро проиндексировать ресурс.
Почти аналогично началось появление подобных систем в СНГ. К ним можно, например, отнести Russian Express, Rambler, Aport и Yandex — так как они тоже используют спайдеров для поиска новых сайтов. Одним из отличий поисковых систем СНГ можно считать то, что они индексируют только сайты СНГ, или проверяют кодировку (язык) текста — как Aport. Вот выдержка из FAQ Yandex:
» Разработка веб-сайта для школы»
... сайта образовательного учреждения 27 2.1 Методика разработки сайта школы 31 2.2 Разработка структуры сайта 31 3 Разработка веб-сайта КГУ «Средней школы №15 села Трудовое». 35 3.1 Задачи и цели сайта ... и размещение web-сайта 51 4.2 Дальнейшее продвижение и поддержка web 53 4.3 Проверка орфографии, ссылок и анализ структуры сайта 56 4.4 Просмотр Web-сайта в браузере и ... имидж и эффективную систему работы ...
Яndex ранжирует документы по вычисляемому параметру «релевантность». Релевантность документа зависит не только от числа слов запроса, найденных в документе, но и от частотных характеристик искомых слов, веса слова или выражения, близости искомых слов в тексте документа друг к другу и т.д.
Заголовки типа «type_Document_Title_here», или «Web Page Title Here», или «Insert Page Title Here», или «Put_Your_Title_Here», или «Заголовок» не украшают ни страницу, ни ее Web-мастера. Помимо этого, многие поисковые системы, в том числе и Yandex, обращают особое внимание на слова, содержащиеся в заголовке. Не стоит брать первые 10 самых поисковых слов из какого-нибудь Top100 и вписывать их в заголовки, комментарии, и просто в текст белым по белому. Во-первых, это не добавляет славы создателю и вызывает естественное раздражение пользователей. Во-вторых, поисковые системы, и Яndex тоже, начинают с этим бороться. Кроме этого, спам увеличивает размер документа и, следовательно, уменьшает контрастность слов в нем.
Но кстати, спама избегать тоже необходимо. Более 30 раз повторенное слово на 1-ой страничке, существенно понизит релевантность страницы в целом. И еще, русские поисковые системы не поддерживают мета тэги, поэтому создавая web-страницу на русском языке, позаботьтесь о том, чтобы в title и находились релевантные фразы, а так же чтобы они присутствовали вверху текста[2].
3.1 История создания поисковой системы GOOGLE
В 1995 г. двое студентов докторантуры Стэнфордского университета — Ларри Пейдж (Larry Page) и Сергей Брин — занимались различными аспектами управления данными. Именно Пейдж в далеком 1996 начал активно использовать Internet для своих исследовательских проектов в области data mining — тогда Web представлял для Пейджа только лишь источник случайно подобранной информации для его разработок. Оба студента входили в рабочую группу MIDAS (Mining Data at Stanford).
Немного позже под управлением Раджива Мотвани (Rajeev Motwani), доцента кафедры информатики и вычислительной техники (Computer Science), Пейдж и уроженец Москвы Брин начали разработку собственной поисковой системы. Уже в то время на Internet — рынке присутствовали различные компании, предоставляющие услуги поиска, однако для будущих докторов наук проект был сродни академической забаве — никто и не думал о быстрой капитализации и создании бизнес — плана. Идея, которая легла в основу поисковой машины, была описана в нескольких научных работах и в то же время довольно проста для понимания.
Сеть содержит огромное количество информации, и определить релевантность отдельно взятой странички большинство поисковиков пытаются по наличию в HTML — файле ключевых слов, которые пользователь ввел в форму поиска. Google же индексирует ссылки, исходящие со страницы, считая каждую ссылку на определенный сайт «голосом», увеличивающим ценность сайта, на который ссылаются. Логично предположить, что на сайт популярный и содержащий полезную информацию ссылаться будут чаще, чем на ресурс бесполезный и неинтересный[10].
Технические средства управления» : «Средства хранения и поиска документов
... схемы, цветные рисунки. Все 9 миллионов слов «Американской энциклопедии» заняли лишь одну пятую часть компактного диска. Развитая сеть институтов и центров хранения и поиска информации непрерывно ведет пере работку дорогостоящего ...
Однако этим определение релевантности сайта не исчерпывается. Полученный результат — условный рейтинг популярности ресурсов — также можно использовать и как источник информации о сайтах, на которые эти самые качественные ресурсы указывают. Таким образом, одна ссылка на вашу страницу с сервера Yahoo! или About.com может оказаться более ценной, чем сотни ссылок с неизвестных домашних страничек — в этом случае Yahoo! и About.com рассматриваются как авторитетные источники и, следовательно, содержат ссылки на высококачественные сайты.
В 1998 г. Google запущен на сервере Стэндфордского университета, и его можно найти по адресу google.Stanford.edu. В то время когда другие стартапы получали финансирование, еще не написав бизнес — плана и не разработав собственного продукта, отцы — основатели Google посчитали, что дополнительные исследования работе поисковой машины никак не помешают, и к моменту основания компании поисковый сервер на основе технологии Page Rank уже проработал больше чем два года. Еще в 1996 г. студенты отметили, что их разработка во многих случаях предоставляла более точные результаты, чем остальные поисковики, а в 1997 Google стал внутренним поисковиком Стэндфордского университета. В том же году Пейдж и Брин идут на первые расходы, связанные с дальнейшим развитием Google, они покупают жесткие диски суммарным объемом в 1 ТВ, что обходится им в 15 тыс. долл. Все растраты пока приходится покрывать собственными кредитными карточками.
В сентябре 1998 г. становится понятно, что для того чтобы развивать технологию и дальше, а также начать лицензировать ее заинтересованным сторонам, необходимо создать компанию. Пейдж и Брин за полгода до защиты докторской диссертации уходят из Стэнфорда и забирают с собой Крега Сильверштейна (Craig Silverstein), который назначается техническим директором. В какой-то момент энтузиасты встречают одного из основателей Sun Microsystems Энди Бехтольшайма (Andy Bechtolsheim), и тот после расспросов о дальнейших планах предприятия тут же выписывает экс — студентам чек на 100 тыс. долл. Тот же 1998 г. обозначился в истории развития Internet резким ростом медиа — компаний. Все поисковые машины, которые до этого предлагали своим пользователям возможность найти необходимую информацию в Сети, внезапно решили заняться предоставлением Internet — услуг: бесплатной почты, биржевых котировок, и прочих атрибутов портала. Когда Пейдж встречается с Джорджем Беллом (George Bell), генеральным директором Excite, тот не высказывает заинтересованности в уникальной поисковой технологии. «Пока наша поисковая система находится в более или менее приличном состоянии, нас это устраивает», утверждает Белл, намекая, что собственно поиск перестает быть объектом интереса для порталов.
И Google пришлось идти своим путем. Вместо того чтобы заняться агрессивным маркетингом и продвижением своего проекта, Пейдж и Брин предпочитают нанять на работу около 150 сотрудников, 20 из которых — доктора наук. Компания не рекламирует себя, закупая миллионы баннеров, не заботится о брендинге и рыночном становлении проекта, не собирается зарабатывать деньги путем показа баннерной рекламы на собственном сайте. Несмотря на такую пассивность с точки зрения маркетолога, известность поисковика продолжает расти, и многие пользователи, привыкшие к обращению к нескольким поисковым системам одновременно, выбирают Google, каждый по каким — либо своим субъективным причинам. Кому-то нравится неброский интерфейс и простота использования, кому-то — скорость работы и не перегруженность сайта рекламой, кому-то — качество результатов поиска.
Известный в США эксперт по usability Джейкоб Нильсен (Jacob Nielsen), который входит в Совет директоров Google, как-то, вспоминая о поисковике, говорит: «Их я считаю своими лучшими клиентами. У них вся компания одержима идеей удобства и простоты использования». Более того, убедившись в благосклонности пользователей к поисковикам с простым интерфейсом, компания Altavista выпускает новую оболочку для своей поисковой машины, заявив о Raging Search (#»607685.files/image002.gif»>
- Рис. 1. Поисковая оптимизация влияет только на основные результаты поиска и не касается платных ссылок, например контекстной рекламы AdWords
Оптимизация сайта должна быть рассчитана на пользователей. Они являются целевой аудиторией сайта, используя поисковые системы для того, чтобы найти его. Излишняя увлеченность специфическими трюками для достижения максимума в топе может не принести желаемых результатов. Оптимизация для поисковых систем — это всего лишь способ быть немного впереди тогда, когда дело касается видимости для поисковых робот.
Название основной страницы сайта может содержать имя сайта или организации, а так же другую полезную информацию, например адрес и краткое описание тематики или услуг[12].

Рис. 3. Пользователь отправляет запрос [поздравительные открытки]
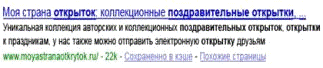
Рис.4. страница появляется в результатах поиска, название в котором будет первой строкой (заметьте, что слова из поискового запроса выделены жирным)

Рис. 5. Если пользователь решит перейти на другую страницу, ее название появится в заголовке окна браузера
Названия других страниц сайта также должны точно описывать их содержание, и могут содержать название сайта или компании.

Рис. 6. Пользователь отправляет запрос [поздравительные открытки с новым годом]

Рис. 7. В поисковой выдаче появляется релевантная страница нашего сайта (ее название описывает ее содержимое)
3.3 Поисковая система — Yandex
Рис.8. Поисковая система Yandex
Официально поисковая машина Yandex.ru была анонсирована 23 сентября 1997 года на выставке Soft tool. Основными отличительными чертами Yandex.ru на тот момент были проверка уникальности документов. Также ключевые свойства поискового ядра Яndex, а именно: учет морфологии русского языка, поиск с учетом расстояния. Тщательно разработанный алгоритм оценки релевантности (соответствия ответа запросу), учитывающий не только количество слов запроса, найденных в тексте, но и «контрастность» слова (его относительную частоту для данного документа), расстояние между словами, и положение слова в документе. Чуть позже в разделе «Сказки» появилась первая сказка Рунета — «Web — гуманизм или чернуха?». А в разделе «Числа» — первая оценка объема Рунета, 5 тысяч серверов и 4Гб текстов.
Через два месяца, в ноябре 1997 года, был реализован естественно-языковый запрос. Отныне к Yandex.ru можно обращаться просто «по-русски», задавать длинные запросы, например: «где купить компьютер», «генетически модифицированные продукты» или «коды международной телефонной связи» и получать точные ответы. Средняя длина запроса в Yandex.ru сейчас — 2,7 слова. В 1997 году она составляла 1,2 слова, тогда пользователи поисковых машин были приучены к телеграфному стилю. В 1998 году на Yandex.ru появилась возможность «найти похожий документ», список найденных серверов, поиск в заданном диапазоне дат и сортировка результатов поиска по времени последнего изменения. За этот год «объем» Русского Интернета удвоился, что привело к необходимости оптимизации поисковых механизмов. И тогда, и сейчас (при объеме в 200 Гб) скорость поиска на Yandex.ru — доли секунды. За 1999 год Рунет вырос на порядок, как в объемах текстов, так и в количестве пользователей. Это был год бурного развития и для Yandex.ru. Новый поисковый робот позволил оптимизировать и ускорить обход сайтов Рунета. Сегодня поисковая база Yandex.ru вдвое больше, чем у ближайших конкурентов. Новый робот позволил предоставить пользователям новые возможности — поиск по разным зонам текста (заголовкам, ссылкам, аннотациям, адресам, подписям к картинкам), ограничение поиска на группу сайтов, поиск по ссылкам и изображениям, а также выделять документы на русском языке. Появился поиск в категориях каталога, и впервые в Рунете было введено понятие «индекс цитирования» — количество ресурсов, ссылающихся на данный.
Независимо от того, в какой форме вы употребили слово в запросе, поиск учитывает все его формы по правилам русского языка. При этом поиск не ограничен лишь словами или фразами. Яндекс отыщет по названию web-страницу компании или файл с нужной картинкой.
3.4 Поисковая система — Rambler
Рис. 9. Поисковая система Rambler
В 1991 году в городе Пущино появилась группа единомышленников, вдохновленных только что появившейся коммуникационной средой Интернет. Дмитрий Крюков, Сергей Лысаков, Виктор Воронков, Владимир Самойлов, Юрий Ершов. Будущие создатели Рамблера поначалу обслуживали радиотехнические приборы в Институте биохимии и физиологии микроорганизмов РАН. Нормальный, оперативный и эффективный обмен данными был необходим для реализации научных целей. В 1992 году компания запускает собственные ftp- и mail-серверы. Через два года — свой первый www-сервер.
год — ключевой для развития русского киберпространства. Именно в этот год Сергей Лысаков и Дмитрий Крюков принимают решение разработать первую русскую поисковую систему для Интернета.
В тот момент в Рунете уже существовало две-три поисковых машины — но они не выдержали проверки временем и быстро исчезли. А Рамблер развивался, эволюционировал.
Рис. 10. Поисковая система Rambler Top 100
Весной 1997 года появляется Rambler Top100 — уникальный рейтинг-классификатор, который не только оценивает на основе объективных данных популярность российских ресурсов, но и позволяет одним «кликом» попасть на них. Веб — мастера стали более тщательно и вдумчиво работать над своими сайтами, стремясь занять в Топ100 более высокие строчки. Rambler Top100 быстро стал универсальным барометром сети, общим стандартом медиа измерений.
Поисковая система содержит информацию о более чем 12 миллионах документов, расположенных на серверах России и стран СНГ. Рамблер обрабатывает ежесуточно не менее 500 тысяч поисковых запросов, сканируя 48 тысяч web-серверов и используя несколько одновременно работающих программ-роботов.
Запрос может состоять из одного или нескольких слов, разделенных пробелами. Могут быть использованы как русские, так и английские слова и словосочетания. По умолчанию находятся только те документы, в которых встретились все введенные Вами слова. Чтобы найти документы, содержащие хотя бы одно слово из запроса, используйте логическую связку Or или выберите на странице детального запроса: «Слова запроса: любое». Чтобы исключить документы, содержащие те или иные слова, укажите на странице детального запроса: «Исключить документы, содержащие следующие слова …».
Рамблер умеет искать слова во всех формах (например, аминокислота, аминокислоты, аминокислотой и т. д.).
Чтобы слово находилось во всех формах, перед ним надо поставить служебный символ ‘#’ . В меню детального запроса такой режим может быть включен для всех слов: «Расширение запроса: все формы слов». Служебный символ ‘@’ перед словом позволяет находить не только само это слово, но и однокоренные слова. В меню детального запроса символу ‘@’ соответствует режим «Расширение запроса: все однокоренные».
По умолчанию наша система ищет слова запроса так, как Вы их ввели, чтобы уменьшить «шум» в найденных документах. Если Вы не помните, как пишется слово, или хотите расширить запрос, можно использовать метасимволы ‘*’ и ‘?’ для обозначения произвольной части слова и произвольного символа.
Ограничить поиск частями документов, такими как название документа, его заголовок, URL и т.п., можно через меню детального запроса «Искать в…».
Можно ограничить поиск документами только на русском или только на английском языке. Для этого надо выбрать соответствующий режим в меню детального запроса «Язык документа…». По умолчанию поиск выполняется по документам на всех языках.
По умолчанию найденные документы сортируются по релевантности. Однако Вы можете потребовать, чтобы вместо этого в начало списка были помещены самые свежие. Для этого надо выбрать соответствующую установку в меню «Сортировать по…» на странице детального запроса.
Вы можете также ограничить поиск документами, созданными в определенный период времени: для этого необходимо на странице детального запроса указать «От даты … до даты …». Можно потребовать, чтобы Рамблер возвращал только те документы, где слова из запроса находятся на минимальном расстоянии друг от друга. Режим «Ограничить расстояние между словами» может быть включен в детальном запросе. Все перечисленные выше правила могут быть использованы совместно друг с другом в необходимой Вам последовательности. По умолчанию результаты поиска выдаются порциями по 15 документов. Меню «Выдавать по…» на странице детального запроса позволяет увеличить это число до 30 или 50. Меню «Форма вывода…» позволяет получать описания документов с увеличенной или уменьшенной подробностью.
3.5 Поисковая система — Yahoo
Рис. 11. Поисковая система Yahoo
Yahoo! — самая известная поисковая машина. Её сайты разбиты по категориям и ключевым словам. Она содержит полезную информацию на своей домашней странице. Может подключаться к другим поисковым машинам.
В ведении находится служба поиска Internet-ресурсов, новостей, карт, рекламных информаций, спортивная информация, бизнес, номера телефонов, персональные WWW-страницы, и email-адреса.
Основная директория содержит: адреса (URL) для Internet-ресурсов и краткое описание для этих связей. Поиск: Все Yahoo страницы предлагают не только простое поисковое окно, но и опции для этого поиска, а также поиск Usenet или Email-адреса. Поиск может ограничиваться указанием определённого промежутка времени. Boolean операторы (и, или) и последовательный поиск также поддержаны. Если Yahoo! не может установить связь достаточно быстро с AltaVista, то в этом случае Yahoo! будет обеспечивать страницу связи с набором инструментов поиска. После того как одна из этих связей выбирается, ключевые слова передаются к поисковой машине на ваше усмотрение.
Средством, облегчающим поиск, является наличие “tip search”(TS) — поиск с помощью “намека”: Yahoo! Является подчиненным справочником, что означает, что система не имеет так много страниц, как поисковые машины, однако задание наиболее общих ключевых слов позволит найти необходимую тему на странице высокого уровня (первая страница, которая возникает перед пользователем при посещении сайта) для организации или компании.
Связи отображаются в соответствии с очерёдностью задаваемых слов последовательностью поиска наряду с их описательным текстом и подчиненной иерархией.
3.6 Поиск по адресам (по URL)
Вы можете искать документы не только по всему русскоязычному Интернету, но и по его части. Самый простой случай — поиск по определенному серверу. Например: url=www.intel.ru собака.
По данному запросу будут найдены все документы на сервере www.intel.ru, содержащие слово «собака». Возможно, вам интересно, а что будет, если написать просто: url=www.intel.ru.
В этом случае вы получите список всех документов, расположенных на указанном вами сервере. Вы можете ограничивать поиск и сильнее — одним из каталогов сервера. Например: url=www.intel.ru/sobaki/ сенбернар.
По данному запросу документы, содержащие слово «сенбернар», будут искаться только в каталоге /sobaki (и его подкаталогах) московского сервера корпорации Intel.
Основные характеристики российских поисковых систем
|
Rambler |
|
|
Адрес |
www.rambler.ru <#»607685.files/image012.gif»> Рис.13. Поисковая система Google Для начала, нужно решить точно, что вы хотите найти. Например, по слову валенки найдется 131 000 тысяча страниц. По запросу, купить оптом валенки в Суздале, всего 259 страниц. Если вы ищете фразу или цитату, напишите ее в кавычках. Вы можете не набирать запрос целиком, а выбрать его уже из появившихся подсказок Рис. 14. Чтобы увидеть ответ прямо в результатах поиска, сразу составляйте вопрос в виде ответа. Например, население санкт-петербурга: Рис. 15 Или Екатерина Великая родилась: Рис.16 Можно искать не только тексты, но и картинки: Рис 17 Так же можно искать видео, карты, новости,… В меню расширенного поиска можно задать поиск информации только на определенном языке: Рис 18 В определенном формате, например, только презентации или же на конкретном сайте. 5. Сохранение информации в сети интернет Сеть Интернет — как огромная библиотека. Она содержит множество Интернет-сайтов, которые состоят из страниц. При помощи компьютера и установленных на нем программ, возможно подключиться к Интернету, чтобы просматривать хранящуюся в нем информацию: тексты, картинки, фотографии, музыку, фильмы, а также сохранять их к себе на диск. Страницы Интернета хранятся не на Вашем компьютере. Он — лишь «окошко», с помощью которого Вы просматриваете сайты. Рис 19 Если возникают ошибки при вводе информации — это не страшно. Невозможно испортить или изменить что-либо в интернете со своего компьютера. Если закрыть нужную страницу — всегда можно открыть ее заново в прежнем виде, нажав на кнопку «Назад» или повторно набрав ее адрес. С одной страницы можно переходить на другие при помощи ссылок — обычно ссылки подчеркнуты и выделены цветом. Рис 20 Когда указатель мышки превращается из стрелочки в значок руки, это значит, что навели его на ссылку. Иногда ссылкой является картинка. Достаточно один раз нажать на ссылку левой кнопкой мыши, и откроется новая страница. Рис 21 С некоторых сайтов можно также отправлять электронные письма и мгновенные сообщения, размещать на них фотографии и вести дневники. Рис. 22 Интернет — это самый легкий путь для общения с друзьями и коллегами в любой точке мира. Интернет содержит множество сайтов на самые разные темы. Заключение С развитием INTERNET появилась возможность быстрого и удобного поиска необходимой документальной информации. Теперь можно не заниматься подбором и изучением огромного количества литературы в книжных магазинах и библиотеках. Информацию можно получить, не выходя из дома или офиса. Для этого нужен только непосредственно сам компьютер, подключенный к INTERNET с установленной специальной программой — браузером, предназначеной для просмотра содержимого Благодаря разнообразию поисковых систем, специально разработанным для рядового пользователя, каждый может без труда отсечь заведомо ненужный поток информации, лишь правильно сформулировав цель поиска. Завершая курсовую работу, можно прийти к выводу, что в сети Интернет хранится очень большой объем как учебной информации по различной тематике в виде статей в электронных газетах, отчетов, справочников, графических изображений, аудио- и видео-файлов так и многого другого. Существуют разные методы поиска учебной информации в сети Интернет: поиск с использованием гипертекстовых ссылок, использование поисковых машин, поиск с применением специальных средств, анализ новых ресурсов. Рассмотренные мною поисковые машины далеки от совершенства. Считается, что идеальная поисковая машина должна отвечать следующим требованиям: . простота в использовании . чётко организованный и обновляемый индекс. . быстрый поиск в базе данных и быстрое реагирование. . надёжность и точность результатов поиска. Масштабы информационных ресурсов и их количество постоянно расширяется. Становится ясно, что база данных не является совершенной. Интеллектуальные агенты — новое направление, лежащее в основе нового поколения поисковых машин, которые могут фильтровать информацию и получать более точный результат. Internet продолжает развиваться с неослабевающей интенсивностью, по сути дела стирая ограничение на распространение и получение информации в мире. Однако в этом информационном океане бывает не очень легко найти необходимый документ, следует также иметь в виду, что в сети наряду с давно действующими серверами возникают новые. Информационные системы, в которых представлены хранение, и обработка информации осуществляются с помощью вычислительной техники, называют автоматизированными, различные виды деятельности и наиболее бурно развивающиеся отрасли индустрии информационных технологий. Список использованной литературы [Электронный ресурс]//URL: https://inzhpro.ru/kursovaya/na-temu-tehnologiya-hraneniya-poiska-i-sortirovki-informatsii/
1. Практикум по информатике: Учеб. пособие / Под ред. Курносова А.П. — Воронеж: ВГАУ, 2004. -239 с. . Крупник А.Б. Поиск в Интернете: самоучитель. — 2-е изд. — СПБ.: Питер, 2004. — 572 с. . Орлов А.А. Нужные программы для Интернета — СПб.: Питер, 2006. — 127 с. . Солоницын Ю.А., Холмогоров В. Интернет. Энциклопедия. — 3-е из. — СПб.: Питер, 2003. — 592 с. . Компьютерные сети и средства защиты информации: Учеб. пособие / Камалян А.К., Кулев С.А., Назаренко К.Н. и др. — Воронеж: ВГАУ, 2003. — 119 с. . Попов В. Практикум по Интернет — технологиям: Учебный курс / В. Попов.-СПб.; М.; Харьков; Минск: Питер, 2002. — 476 с.:ил. . Компьютерные сети и средства защиты информации: Учебное пособие / Камалян А.К., Кулев С.А., Назаренко К.Н. и др.-Воронеж: ВГАУ, 2003.-119 с. . Основы современных компьютерных технологий. Под ред. Хомоненко А.Д. — Корона-принт, СПб 1998. . Персональные компьютеры в сетях TCP/IP. Крейг Хант; перев. С англ. — BHV-Киев, 1997. . Павел Храмцов «Поиск и навигация в Internet».://www.osp.ru/cw/1996/20/31.htm . Обучение Интернет — профессиям. Search engine Expert.://searchengine.narod.ru/archiv/se_2_250500.htm . Андрей Аликберов «Несколько слов о том, как работают роботы поисковых машин».://www.citforum.ru/internet/search/art_1.shtml |